1. Introduction & Core Concepts
Introduction
Section titled “Introduction”Collecting and disseminating personal data has become ubiquitous across institutions, governments, and organisations, posing significant privacy concerns, especially for vulnerable communities. Traditional anonymisation techniques have long been used to manage this risk, but they carry well-documented limitations.
These traditional, ad-hoc techniques fall into two broad groups: statistical disclosure limitation methods, such as generalisation, suppression, and k-anonymity; and the release of aggregates, such as counts and means. Both provide protection only in a heuristic or empirical sense, and require careful analysis of the adversary’s computational power, auxiliary information, and the current threat landscape. Moreover, releasing multiple aggregates increases the risk of reconstructing the original data, and requires the accumulated risk to be reassessed with each release. These limitations have led to real-world re-identification incidents, for example in health records, aggregated mobility data, credit-card metadata, and mobile usage data, and to increased privacy risks.
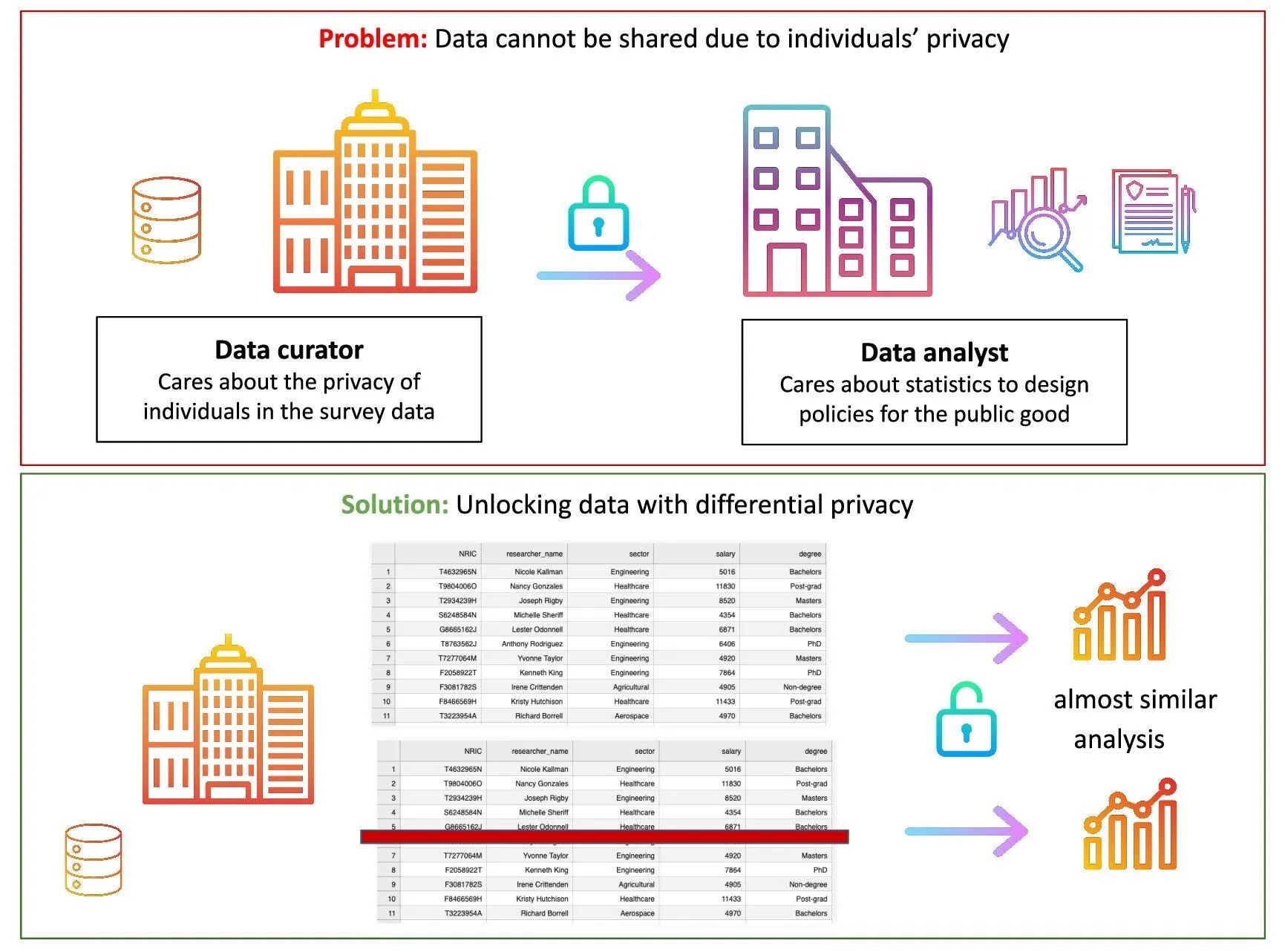
The need for stronger protection has driven increased support for and adoption of differential privacy by both government institutions and commercial enterprises, enabling the release of datasets that could otherwise not be shared. Differential privacy offers four properties that distinguish it from traditional methods:
- A quantifiable, provable guarantee about the worst-case privacy risk.
- No assumption about auxiliary information. An attacker with detailed information, or access to future dataset releases, still gains no advantage.
- No assumption about the adversary’s computational power. The guarantee holds even against unlimited compute, and can prevent any arbitrary threat.
- Quantifiable accumulated risk from releasing multiple statistics about individuals.
This guide explains the core concepts of differential privacy: what it is, how it works, and how it is applied. It then points to our 2023 work comparing the open-source tools that implement differential privacy, benchmarking their performance, and deploying them at scale.
What is Differential Privacy?
Section titled “What is Differential Privacy?”Overview
Section titled “Overview”Differential privacy is a notion of privacy that enables the release of data, or of results from data analysis, with a mathematical guarantee of privacy. It focuses on data-releasing algorithms, such as those computing the mean, sum, or count of a dataset, that take in analytical queries and produce outputs altered in a controlled, random manner.
Such algorithms are considered differentially private if, based on the outputs, it is difficult to determine whether any individual’s information was included in the original data. This is accomplished by guaranteeing that the algorithm’s behaviour hardly changes whether or not a single individual is part of the data.
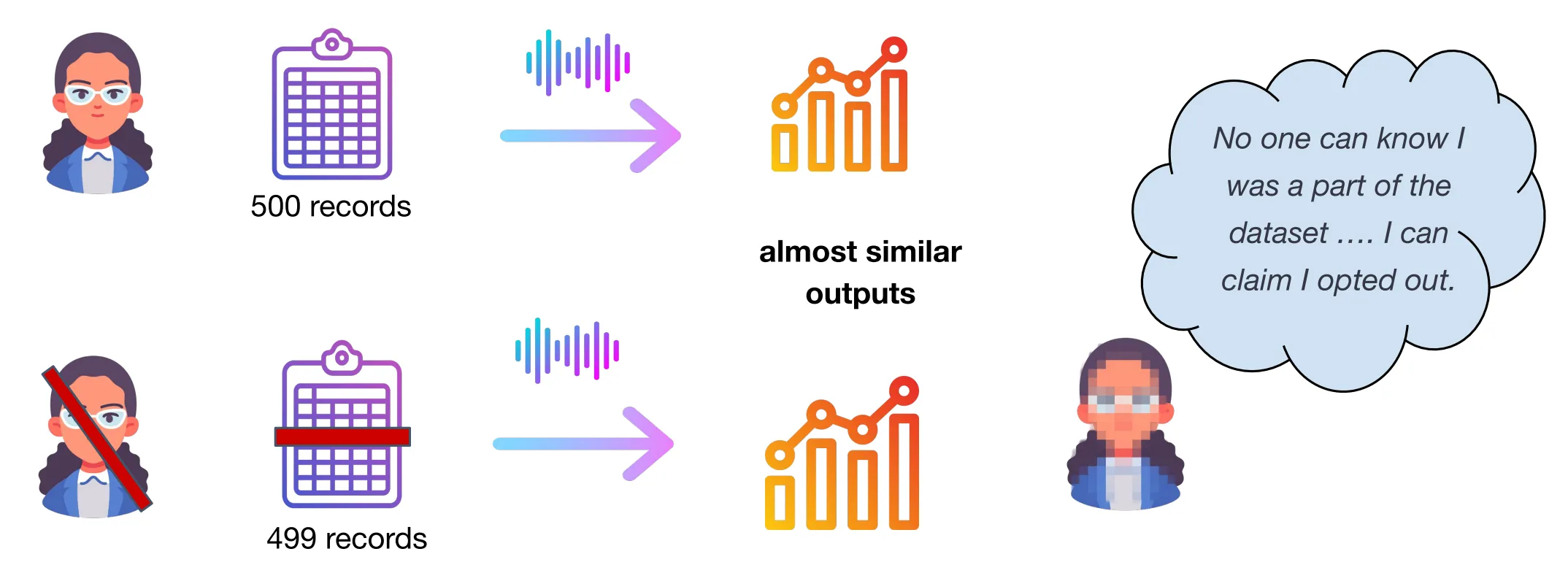
To achieve this similarity, differential privacy adds a calculated amount of randomness, or noise, to the analytical query. The magnitude of the noise, which determines the degree of privacy, depends on the type of analysis, and must be sufficient to hide the largest contribution that any one individual could make to the output.
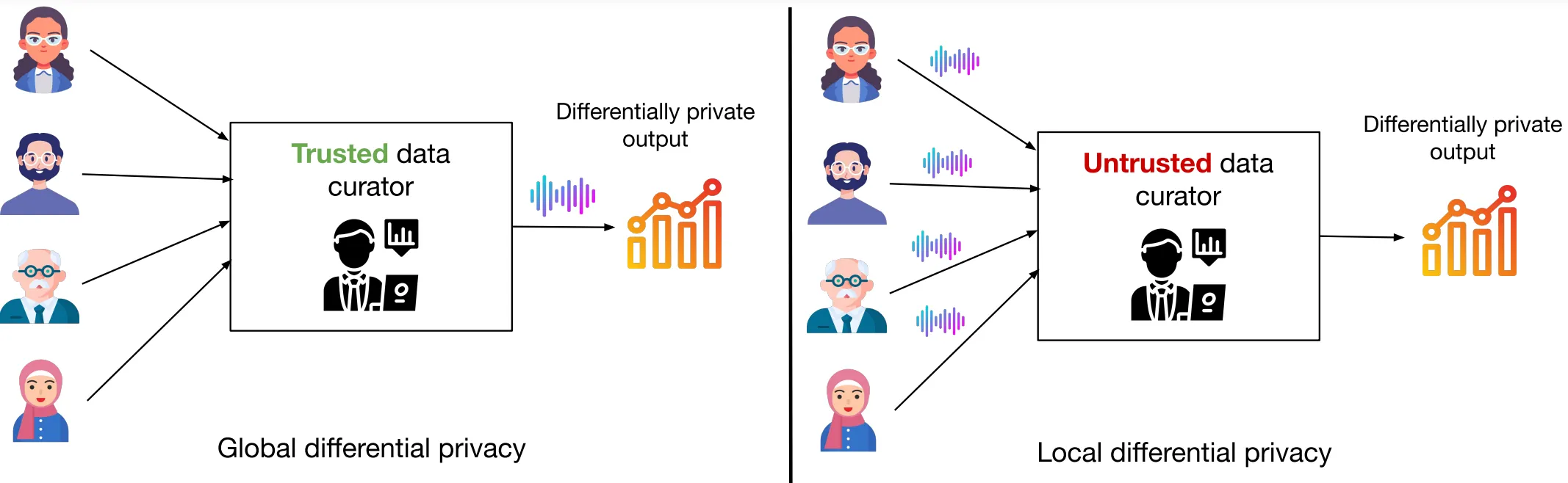
Global and Local Differential Privacy
Section titled “Global and Local Differential Privacy”Noise can be added at two different points, corresponding to different levels of trust in the data curator.
- Global mode. Noise is added directly to the aggregates. This assumes a trusted data curator that holds the sensitive information.
- Local mode. Noise is added to individual data points before aggregation. This assumes an untrusted data curator, and maintains privacy at the source before data leaves the data subject’s control.
Global differential privacy is more widely adopted because it produces more accurate results than the local mode for the same level of privacy protection. The choice of mode, however, depends on the level of trust in the data curator.
A Simple Mathematical Interpretation
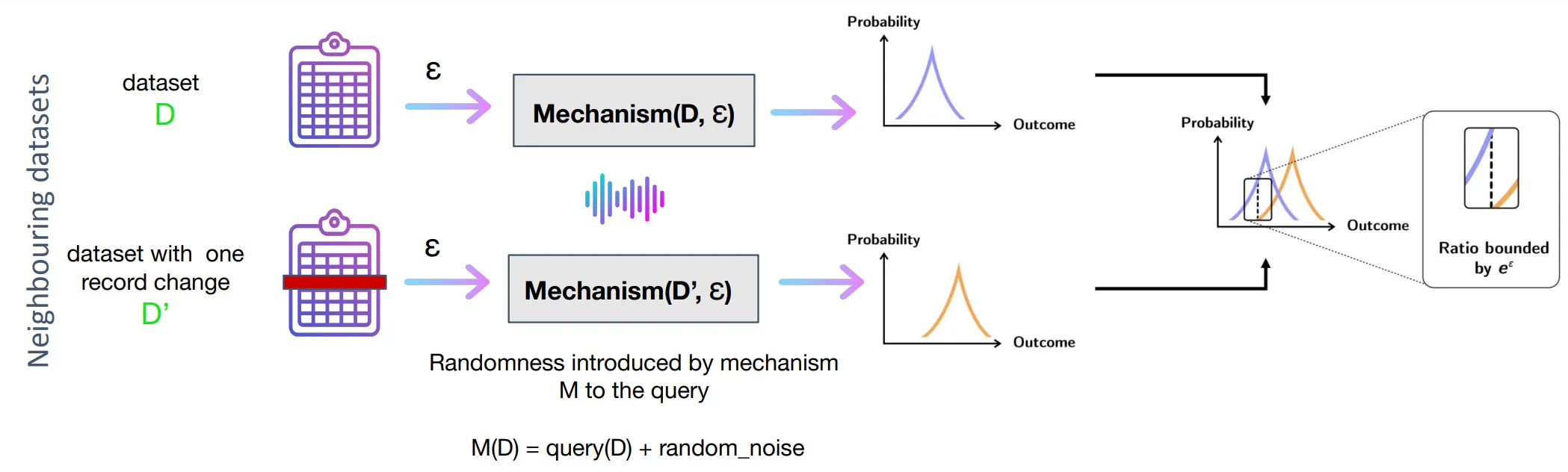
Section titled “A Simple Mathematical Interpretation”The outcome of a differentially private analysis is similar whether or not an individual’s data is included. By similar, we mean that the probabilities are close. This can be made precise.
Suppose exactly one person’s data is added or removed from a dataset. These are called neighbouring data, denoted D and D’, that differ in exactly one person’s record. A mechanism M (the differential privacy term for an algorithm) adds random noise from a probability distribution to the analytical query. Then all possible outputs O of M are probabilistically similar for D and D’. The degree of similarity depends on the privacy loss parameter ε (epsilon): the smaller it is, the more similar the outputs from neighbouring data. Formally, for all neighbouring datasets and all output sets:
Pr[ M(D) ∈ O ] ≤ e^ε × Pr[ M(D’) ∈ O ]
Choosing a Value for Epsilon
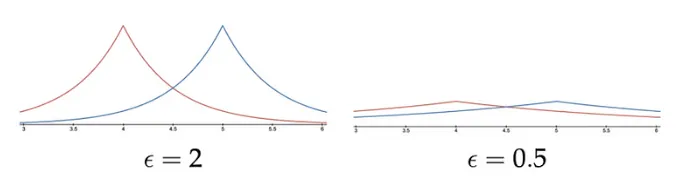
Section titled “Choosing a Value for Epsilon”There is no consensus on the choice of ε, and its value depends on the specific context and use case. It is generally recommended to set a positive ε of less than 1 to achieve conservative privacy. However, practitioners may sometimes use higher ε values to achieve greater analysis accuracy. A larger ε may compromise the privacy guarantee, which underscores the need to weigh the privacy and accuracy trade-off carefully when selecting ε.
This regularly updated article presents thorough compilations of ε values used in real-world applications, ranging from low to high.
Key Properties
Section titled “Key Properties”Differential privacy has several key properties, summarised in the figure below. The most relevant for this guide is composition, the property that lets the privacy losses of multiple analyses be added up; we use it in the next example and in the privacy budget.
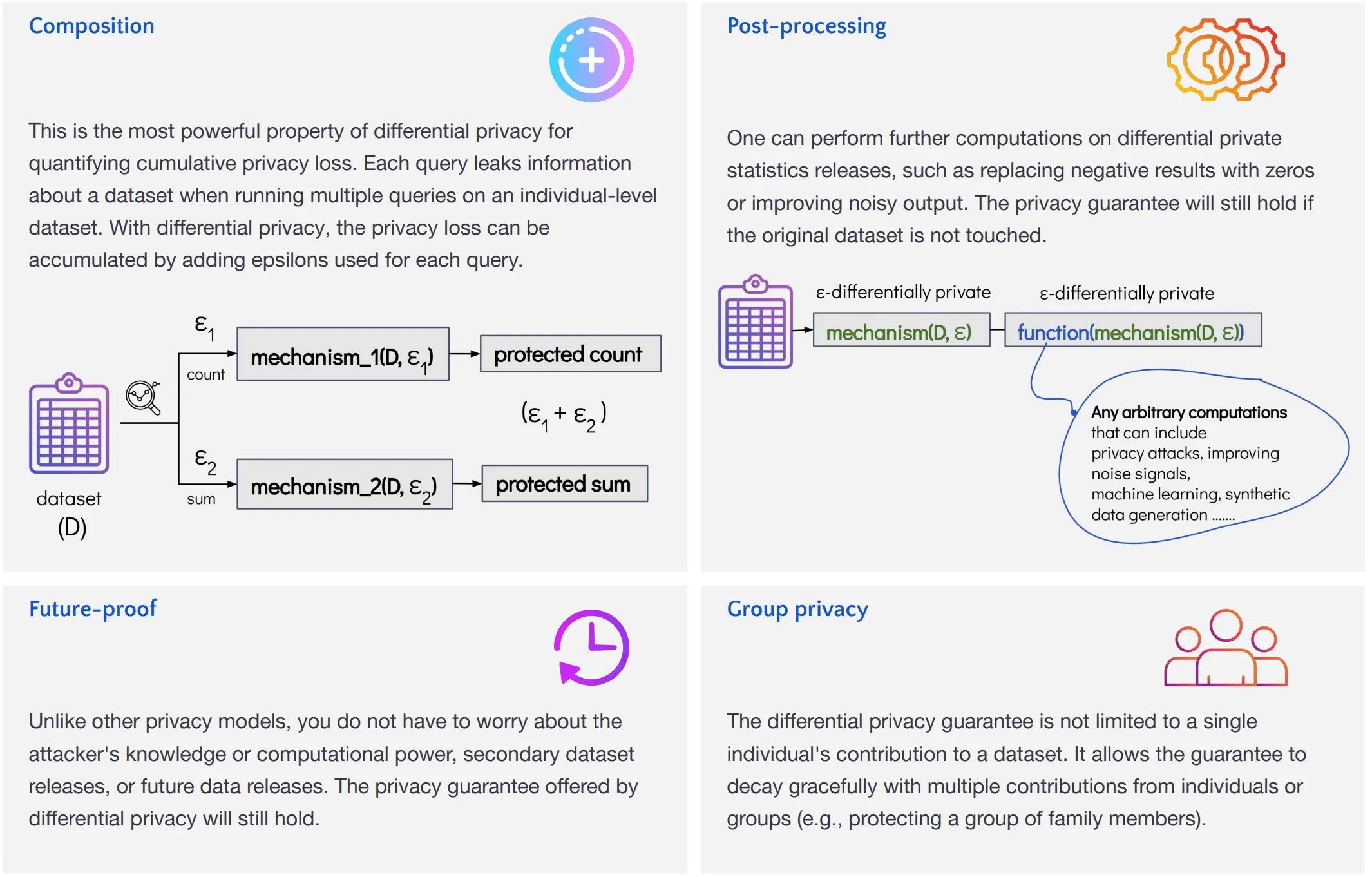
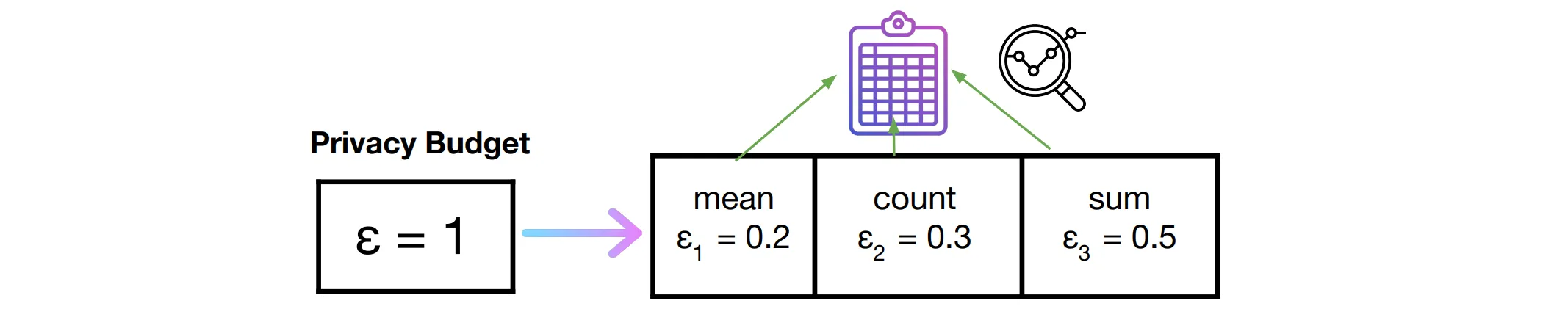
The Privacy Budget
Section titled “The Privacy Budget”Because composition allows epsilons to be added up to quantify cumulative privacy loss, ε is also called a privacy budget. It allows the type and number of data queries to be restricted in order to prevent breaches. A useful analogy is shopping with a fixed budget, where you prioritise which items matter most for your wardrobe. Similarly, with a privacy budget, you might prioritise the accuracy of certain queries and allocate a larger portion of the budget to those.
Setting a privacy budget depends on the data holder’s risk tolerance. Overspending it can increase the privacy risk, such as exposure to reconstruction attacks.