3. Mitigating Privacy Risks
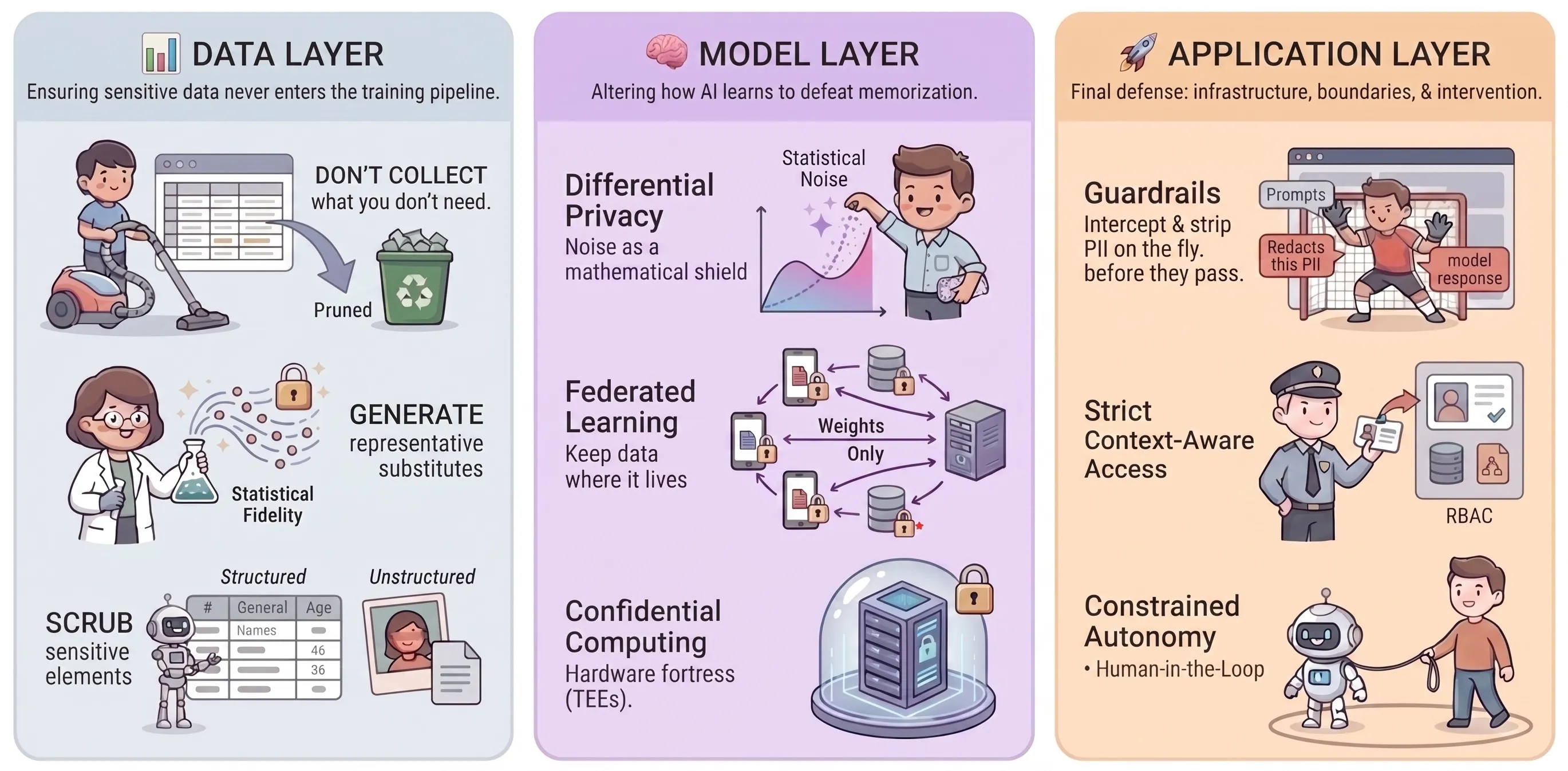
Mitigating privacy risks across the three layers of the AI lifecycle (Data, Model, and Application). Image generated with Gemini.
Once privacy risks are identified and rigorously measured, the final pillar is active mitigation. Mitigation cannot be treated as a one-size-fits-all patch applied at the end of development; it requires targeted, engineered interventions deployed precisely at the layer where the vulnerability originates. Below, we explore the mitigation strategies across three critical stages: the Data Layer, Model Layer, and Application Layer.
📊 Data Layer
Section titled “📊 Data Layer”Mitigation at the data layer focuses on a fundamental principle: ensuring sensitive information never enters the training pipeline in a vulnerable state. To achieve this, organisations should adopt a strict, sequential defence hierarchy: Minimisation, Substitution, and Sanitisation.
1. Data Minimisation and Governance
Section titled “1. Data Minimisation and Governance”The golden rule: Don’t collect or retain what you don’t absolutely need.
The ultimate preventative measure is reducing the raw data footprint. Before ingestion, apply strict necessity tests and leverage automated data discovery tools to map sensitive flows. Aggressively prune datasets to drop features, columns, or records that lack predictive utility. Furthermore, implement strict data retention policies to ensure information is destroyed after its legitimate primary use expires. By shrinking the dataset, the attack surface for both model memorisation and re-identification is immediately reduced.
2. Synthetic Data Generation (SDG)
Section titled “2. Synthetic Data Generation (SDG)”The alternative: If you need real-world statistical fidelity, generate a representative substitute.
When training requires data that reflects the complex distributions, correlations, and behaviours of real-world populations, use artificial datasets rather than raw production data. Synthetic data mimics these statistical properties without exposing actual sensitive information of individuals. However, SDG alone does not guarantee privacy as the generative models may still memorise outliers. For more rigorous privacy protection, SDG can be paired with Differential Privacy. This injects calibrated statistical noise into the generation process, ensuring that the presence or absence of any single individual cannot be inferred from the final synthetic output. For more details on SDG, refer to our Synthetic Data Primer.
3. Data Sanitisation and Obfuscation
Section titled “3. Data Sanitisation and Obfuscation”The last resort: If you must use real data, scrub the sensitive elements.
When the use of real, production data is completely unavoidable, sensitive attributes must be obfuscated before use. The appropriate technique depends on the data modality and the required balance between privacy and utility:
-
Structured Data (Tabular):
- Direct identifiers: Should be completely dropped, redacted, or replaced using strict tokenisation or format-preserving encryption to maintain valid database schemas without exposing the raw data. Avoid simply hashing low-entropy identifiers (e.g., phone numbers), as this leaves them highly vulnerable to brute-force and dictionary attacks.
- Quasi-identifiers: To protect against linkage attacks, where adversaries combine indirect identifiers like ZIP codes and birthdates to re-identify individuals, apply formal anonymity techniques like k-anonymity, l-diversity, or t-closeness via generalisation (e.g., bucketing exact ages into broader ranges).
- Numerical features: Differential Privacy can be applied by injecting calibrated statistical noise. This provides a mathematical guarantee that the presence or absence of a single individual in the dataset will not significantly affect the output, though it requires careful tuning of the privacy budget to avoid degrading utility.
-
Unstructured Data: This requires stripping both direct and contextual identifiers that may reside within text, images, or audio.
- Text data: Sanitisation pipelines should utilise Named Entity Recognition (NER) and Natural Language Processing (NLP) to redact PII before it reaches the model’s tokeniser.
- Image data: Employ computer vision techniques to blur or redact sensitive parts (e.g., faces and licence plates).
- Audio data: Use acoustic processing to alter voice biometrics.
- Embedded metadata: Use automated filters to systematically strip metadata (like EXIF geolocation) prior to model ingestion.
🧠 Model Layer
Section titled “🧠 Model Layer”Mitigation at the model layer focuses on altering how the AI learns and processes information, specifically engineered to defeat memorisation and reverse-engineering attacks.
1. Differential Privacy (DP)
Section titled “1. Differential Privacy (DP)”The mathematical shield: Noise as a privacy guarantee.
When applied at the model layer, DP (through techniques like Differentially Private Stochastic Gradient Descent) obscures the influence of any single individual’s data point on the model’s final weights, providing a statistical guarantee of privacy. Rather than altering the underlying raw data, this approach intervenes during the learning process itself by clipping the model’s gradients and injecting a mathematically calibrated amount of noise directly into those gradients during training updates. As injecting noise inherently involves a privacy-utility trade-off, there is a need to carefully balance the protection of individuals without severely degrading the model’s performance.
2. Federated Learning
Section titled “2. Federated Learning”The decentralised approach: Keep data where it lives.
Rather than pooling sensitive data into a vulnerable centralised server for training, federated learning pushes the model training directly to local devices (the “edge”). Only the updated model weights (not the raw data) are sent back to the central server. Because these transmitted weights can still be vulnerable to gradient inversion attacks, where attackers exploit the shared model updates to reconstruct training data, federated learning is typically paired with Secure Aggregation or Differential Privacy.
3. Confidential Computing (Trusted Execution Environments)
Section titled “3. Confidential Computing (Trusted Execution Environments)”The hardware fortress: Encrypt data even while in use.
Operating at the infrastructure layer, hardware-based secure enclaves (TEEs) directly protect model weights and execution. For highly sensitive workloads (such as healthcare or financial modelling), models can be trained and executed inside these enclaves. TEEs encrypt data while it is actively in use, ensuring that not even system administrators, hypervisors, or cloud providers can view the data or the model parameters during processing.
4. Cryptographic Computing
Section titled “4. Cryptographic Computing”The cryptographic approach: Training in the dark.
Homomorphic Encryption (HE): When applied to model training, HE allows a server to compute model updates (like gradient calculations) directly on encrypted training data. Data owners encrypt their datasets before uploading them to the compute environment; the learning algorithm then processes the data and updates the model’s weights mathematically without ever decrypting the underlying inputs. This ensures that the server training the model never has access to the plaintext training examples. The caveat here is that the use of HE introduces massive computational overhead, especially with the computationally expensive polynomial approximations needed for non-linear activation functions (like ReLU).
Secure Multi-Party Computation (SMPC): This protocol enables collaborative model training across multiple isolated organisations (such as different hospitals or banks) without them having to expose their sensitive datasets to one another or a central server. The mathematical workload of training the model is cryptographically split across the participants. They jointly compute the model updates so that the final trained model learns from the collective data, but no single party ever gains access to another’s raw data during the training cycle. While HE suffers from a computational bottleneck, SMPC suffers from a communication bottleneck. Jointly computing model updates requires constant, massive, back-and-forth data exchange between all participating nodes. Because of this network strain, pure SMPC training is typically constrained to a small number of participants with high-bandwidth, low-latency connections.
🚀 Application Layer
Section titled “🚀 Application Layer”Mitigation at the application layer acts as the final line of defence, focusing on secure infrastructure, user boundaries, and real-time intervention.
1. Real-Time Guardrails
Section titled “1. Real-Time Guardrails”The active filter: Intercept and strip sensitive data on the fly.
Applications powered by Generative AI require active, real-time monitoring of both user inputs (prompts) and AI outputs. Integrating PII guardrails directly into the application flow enables the interception and redaction of PII from prompts before it leaves the secure environment. Output PII guardrails should also be implemented to catch and redact any sensitive information or memorised data the model might attempt to provide before it reaches the user.
2. Strict Access Control
Section titled “2. Strict Access Control”The access gatekeeper: Restricting context to the user’s exact permissions.
When AI systems interact with internal databases, vector stores, or external plugins, they must not operate with overarching unrestricted access. Instead, both Retrieval-Augmented Generation (RAG) architectures and autonomous AI agents require strict Role-Based Access Control (RBAC) or Attribute-Based Access Control (ABAC). For example, the following can be implemented:
-
User Context Inheritance: The AI’s runtime environment must dynamically inherit the invoking user’s exact permissions. This prevents a RAG system or an autonomous agent from fetching confidential records on behalf of an unauthorised user.
-
Vector Search Entitlements: In RAG setups, access control must be enforced at the query level. The application must verify the user’s identity and apply necessary metadata filters to the vector database before retrieving context and generating a response.
Because an AI cannot leak information it cannot see, enforcing strict identity propagation is critical. This ensures that the model’s contextual window is populated exclusively with data the user is explicitly authorised to view.
3. Constrained AI Autonomy
Section titled “3. Constrained AI Autonomy”The Supervised Delegate: Restricting agentic actions to prevent unintended data exposure.
With increasing use of autonomous agents capable of taking actions across systems, the risk of accidental or manipulated data exposure expands significantly. The application layer must tightly constrain what data an agent can access, process, and transmit during its execution.
-
Preventing Data Exfiltration: Guardrails must actively detect and neutralise prompt injection attacks. In a privacy context, these adversarial inputs are often designed to trick the LLM into ignoring data sanitisation rules, bypassing access controls, or regurgitating private system context and cross-user PII.
-
Minimising Tool-Based Exposure: Agentic toolsets must be heavily scoped using the principle of least privilege. If an agent is tasked with summarising public documentation, it should not have the technical capability to invoke tools that read internal emails or CRM records. This mechanically limits the potential for broad privacy breaches if the agent hallucinates or goes off-course.
-
Human-in-the-Loop (HITL) for Data Egress: Enforce strict authorisation checkpoints before an agent can execute privileged API calls. This ensures a human can review the specific data payload, preventing the AI from autonomously transmitting unmasked personal or sensitive data to untrusted third-party services.
4. Zero Data Retention
Section titled “4. Zero Data Retention”The clean slate: Avoid retaining conversational PII.
Design the application layer to avoid logging user interactions in plain text or retaining them for downstream model training without explicit, opt-in consent. When storing chat history is necessary to enable features like cross-session memory, engineer the storage pipeline to actively minimise privacy risks. This can be achieved by decoupling interaction logs from personally identifiable user metadata, mandating encryption at rest for all stored conversational data, and enforcing strict Time-to-Live (TTL) policies to automatically purge stale chat histories. Together, these strategies significantly reduce the exposure footprint of conversational PII in the event of an internal misuse incident or external breach.
5. Transparent Privacy Controls
Section titled “5. Transparent Privacy Controls”The clear contract: Empowering users with granular consent.
As the application layer is the primary interface with the end user, it serves as the legal and ethical locus for managing consent. Applications should surface clear, contextual privacy notices explaining exactly how the AI processes, stores, and utilises data at the moment of interaction. Granular consent toggles should also be provided to allow explicit, opt-in (rather than opt-out) control over whether their interactions, feedback, or uploaded documents are logged or utilised for continuous model training.
🔄 Continuous Loop: Identify and Measure Residual Risks
Section titled “🔄 Continuous Loop: Identify and Measure Residual Risks”Mitigation is not the final step; it is part of an ongoing, iterative cycle. Even with robust mitigations in place across the Data, Model, and Application layers, zero risk is rarely achievable.
Organisations must continuously identify and quantify residual privacy risks, the vulnerabilities that remain after interventions are applied. This requires looping back to the identification and measurement phases: re-evaluating the system with privacy attacks and audits to ensure that the mitigations are effective and that the remaining risk falls within an acceptable threshold. As models evolve and new data is introduced, this continuous feedback loop ensures that privacy protections remain resilient against emerging threats.