1. What is Synthetic Data?
At its core, synthetic data is data that is not collected from real-world events such as captured by cameras, written in doctor’s notes, recorded from voices, or gathered from user interactions like surveys. Instead, it is algorithmically generated using statistical and generative models that aim to replicate the statistical properties—including distributions, correlations, semantics, and temporal dynamics—and relationships of real data. Synthetic data can reduce direct exposure of real records, but it does not provide formal privacy guarantees on its own; strong protection requires combining it with safeguards.
This guide focuses on synthetic data’s broadly accepted definition: statistical and generative synthesis methodologies that can learn and replicate the patterns and statistical properties of real data across text, images, tabular data, audio, and video. These methods include statistical models, Generative Adversarial Networks (GANs), diffusion models, transformers and other advanced AI techniques that go beyond manually written rule-based data generation.
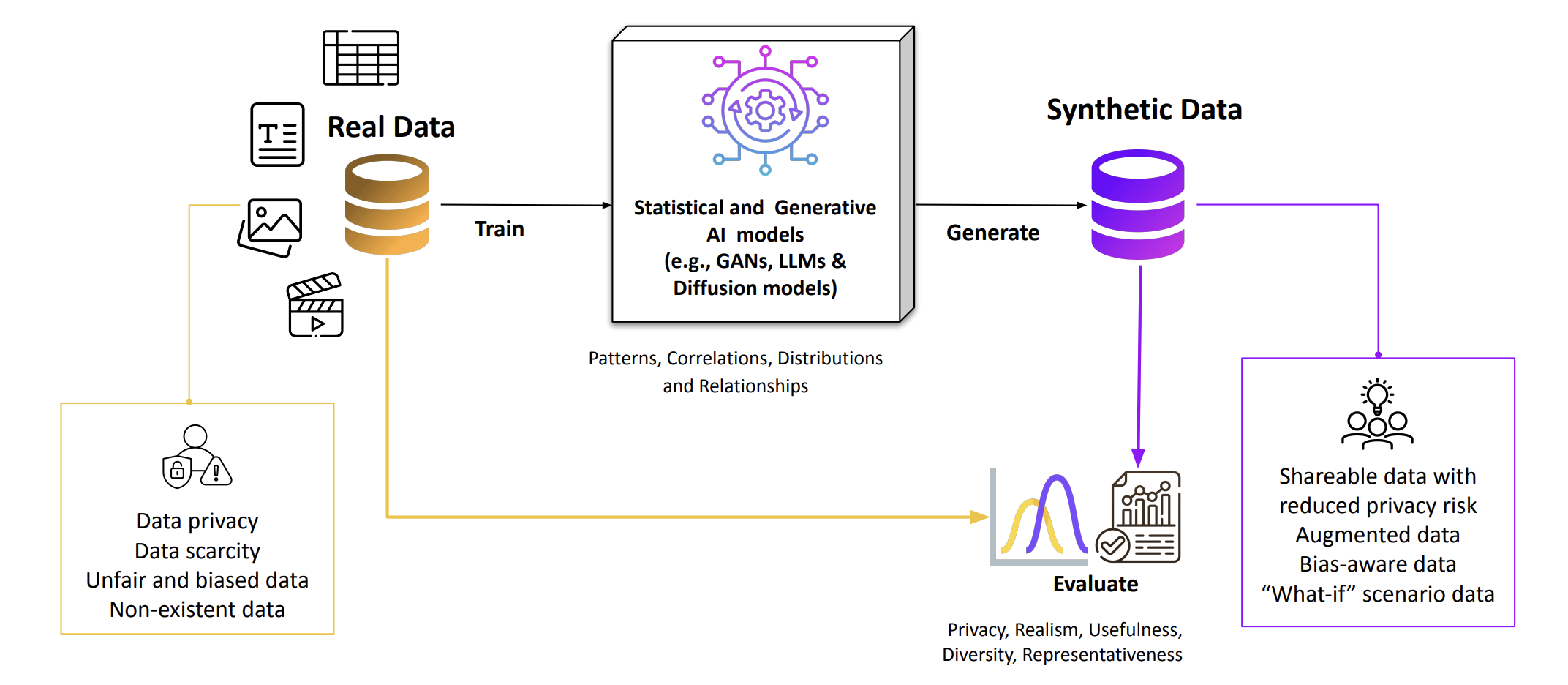
Figure: Overview of synthetic data generation and its relationship to
real-world data
Additionally, recent developments in foundation models—particularly Large Language Models (LLMs)—are expanding synthetic data generation beyond traditional approaches. These models can generate diverse data types including text, structured tabular data, code, and other formats by leveraging patterns learned from vast training datasets, enabling synthesis even when limited domain-specific examples are available.
Data Formats and Types
Section titled “Data Formats and Types”| Data Type | Examples | Use Cases |
|---|---|---|
| Structured Data | Database tables, spreadsheets, time-series measurements from sensors | Financial modeling, predictive analytics, system monitoring |
| Semi-Structured Data | JSON files, log entries, API responses | API testing, system integration, anomaly detection |
| Unstructured Data | Documents, images, audio recordings, video content, social media posts | Content analysis, computer vision, natural language processing |
| Multi-Modal Combinations | Text paired with images, video with audio transcripts, or any combination that reflects complex real-world scenarios | Multimodal AI training, content generation, automated captioning |
Synthetic data spans nearly every format encountered in real-world applications and touches almost every sector, from finance and healthcare to automotive, government, industrial applications, and research:
Varied Real-World Applications
Section titled “Varied Real-World Applications”| Sector | Applications |
|---|---|
| Healthcare Innovation | Synthetic Electronic Health Records (EHRs) and lab-test datasets enable medical research and AI development while protecting patient privacy |
| Autonomous Systems | Generation of rare or hypothetical driving scenarios—unusual weather conditions combined with unexpected pedestrian behaviors |
| Voice and Accessibility | Synthetic voices power accessibility applications, voice-over testing, and interactive systems |
| Creative and Media Industries | AI-generated visuals, animations in specific artistic styles (like Studio Ghibli aesthetics), and realistic video game environments |
| AI Safety and Research | Synthetic examples for improving AI reasoning capabilities, generating counterfactuals for model testing, and creating red-teaming scenarios |
Synthetic data offers organizations a new approach to working with data—expanding possibilities when real data is unavailable, sensitive, or insufficient for specific use cases. However, like any analytical tool, its value depends entirely on proper application, rigorous evaluation, and responsible governance.
The next chapter explores five key capabilities of synthetic data—along with their caveats—that are becoming essential for organizations navigating today’s data challenges.
Footnotes
Section titled “Footnotes”-
Simulation-based synthesis is a fast-growing pillar for robotics/embodied-AI: high-fidelity 3D simulators (e.g., NVIDIA Isaac Sim/Omniverse) and curated synthetic scene sets (e.g., HSSD-200) are now standard infrastructure, and recent robot foundational models (e.g., NVIDIA GR00T) explicitly generate large synthetic trajectory datasets in simulation to accelerate training. ↩