5. Privacy-preserving Data Synthesis
While synthetic data attempts to break direct one-to-one mappings between real and synthetic records, its “synthetic” label alone does not guarantee privacy. Like any AI/ML model, a generator—also called a synthesizer—learns patterns from real data, and under certain conditions, those patterns can leak sensitive or identifiable information.
What is a privacy leak? When synthetic data contains information that could identify or reveal sensitive details about real people from the real dataset. For e.g., if a synthetic patient record is nearly identical to a real patient’s record, it could expose that person’s medical information.
A context-driven privacy evaluation is therefore essential before sharing or using synthetic data in sensitive scenarios. Privacy risks should be assessed using complementary methods, each providing a different lens on potential leakage.
Two-Pronged Privacy Risk Evaluation
Section titled “Two-Pronged Privacy Risk Evaluation”As no single metric can capture every vector of privacy leakage, our two-pronged methodology includes two type of evaluation metrics:
- Empirical Privacy Risk Assessment (Smoke Testing): Computationally lightweight proxy metrics that detect memorization. These serve as a fast sanity check and first line of defense.
- Attack-Based Evaluation (Adversarial Testing): Rigorous modeling of specific privacy attacks (singling out, linkability, inference, membership inference) under a defined threat model. This provides a realistic measure of an attacker’s potential success.
Before any evaluation begins, strictly partition your data:
- Dtrain — the real data ingested by the generator for training.
- Dcontrol — a holdout set representing the general population. The generator must not see this data.
- Dsynth — the generated synthetic dataset.
The control partition is essential because it provides the counterfactual baseline necessary to measure excess risk. It answers a critical question: is an attacker exploiting leaked information specific to the individuals in the training data, or simply leveraging the broader, population-level trends the model was supposed to learn? By comparing evaluation metrics on Dtrain against Dcontrol, we isolate genuine privacy leakage from benign pattern learning.
The following subsections sections walk through each type of evaluation metrics.
1. Empirical Privacy Risk Assessment: Smoke Testing
Section titled “1. Empirical Privacy Risk Assessment: Smoke Testing”Empirical checks are a quick way to flag potential privacy leaks—situations where synthetic data reveals information about real individuals from the real dataset. These tests look for signs that the synthesizer memorized specific real records instead of learning general patterns.
Common “smoke tests” include:
-
Distance-based measures (similarity/proximity checks): Compare synthetic records directly against the real dataset to find close matches. If many synthetic records closely resemble real ones, this suggests the generator copied rather than learned patterns.
-
Duplicate detection: Check if any synthetic records are exact copies or near-duplicates of real records. Exact matches are clear privacy violations.
-
Outlier detection: Identify unusual synthetic records (rare combinations of attributes) and check if they match real outliers. Copying rare cases is particularly risky for privacy.
Figure 1: Example of distance-based privacy evaluation using DCR (distance
to closest record) measurements to evaluate the overall distance between
real and synthetic data. For every point of synthetic data (blue), the
closest point of real data (black) is identified. The DCR (red line) is
the distance to that real data point. In this example, there are three
columns of data (X, Y and Z); the same DCR metric can be applied to any
number of columns.
Image reference:
SDV DCRBaselineProtection
2. Attack-Based Evaluation: Adversarial Testing
Section titled “2. Attack-Based Evaluation: Adversarial Testing”Attack-based evaluations assess privacy risks by testing how vulnerable or safe synthetic data is to privacy attacks. Before interpreting attack results, consider your threat model: what are the attacker’s goals, background knowledge, and available resources?
Common “adversarial tests” include:
-
Membership inference: Determine whether a target individual’s record was used in training by probing model outputs or analyzing the synthetic release.1
-
Attribute inference (sensitive-attribute disclosure): Infer a hidden/sensitive attribute about a target using patterns learned by the synthesizer or models trained on the synthetic data.
-
Record reconstruction: Recover an approximate training-set record (e.g., a near-duplicate) from model behavior or the synthetic dataset.

Figure 2: Privacy attack goals against synthetic data arranged along an
information-gain spectrum: membership inference, attribute inference, and
record reconstruction.
Attack-based testing2 provides useful risk signals because it works under realistic attacker assumptions, but it must be framed within a defined threat model to avoid over- or underestimating risk.
Interpreting Privacy Test Results
Section titled “Interpreting Privacy Test Results”Privacy test results require careful contextual interpretation. The following guidelines apply across all tools and evaluation approaches:
-
Consider your specific situation: Test results depend on who might attack your data and how they would use it. For e.g., if you’re sharing data publicly, privacy attacks are more concerning than if you’re only using synthetic data internally within your organization.
-
High scores don’t always mean high risk: A tool might report that an attack “succeeded,” but this could require the attacker to have unrealistic access to information or computational resources. Consider whether the attack scenario actually applies to your real-world situation.
-
Dataset specifics: Results vary significantly based on data size, dimensionality, and data quality. For e.g., if your real dataset is small or has many unique records, privacy tests will often show high vulnerability regardless of how good your synthetic data generator is. This reflects the inherent challenge of protecting privacy in small, diverse datasets.
-
Baseline comparisons: Always compare against appropriate baselines (e.g., attacks on real data) to interpret results meaningfully. If attacks succeed equally well on real and synthetic data, the issue may be dataset characteristics rather than privacy leakage.
Differential Privacy: Formal Guarantees
Section titled “Differential Privacy: Formal Guarantees”Differentially private
synthesizer training provides a mathematical guarantee that the trained model parameters, and any subsequent model outputs, are relatively unaffected by the addition, removal or change of any single user’s training examples. Unlike empirical or attack-based testing, DP’s protection does not rely on assumptions about attacker behavior.
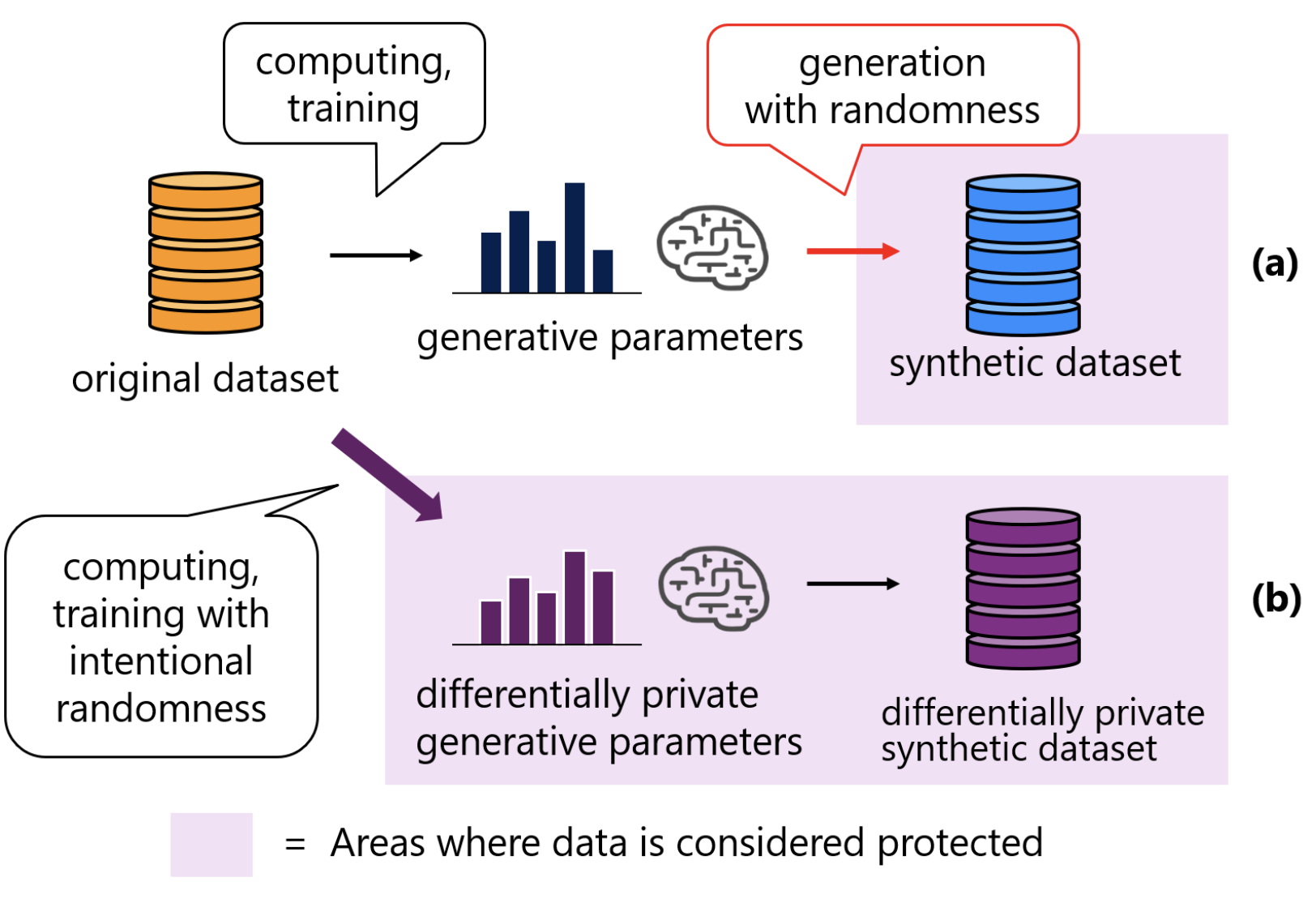
Figure 3: Synthetic data generation without and with differential privacy
(DP). (a) Non-DP: a model learns patterns from real data to sample
synthetic records—often high utility but no formal privacy guarantee and
potential inference/memorization risks. (b) DP: training uses clipping and
calibrated noise (tuned to (ε,δ)), yielding a model and synthetic outputs
with a formal individual-level DP guarantee, typically with some utility
trade-off.
Image reference:
On Renyi Differential Privacy in Statistics-Based Synthetic Data Generation
The guarantee works by adding carefully calibrated randomness (noise) to the synthesizer’s training process measured by privacy parameters ε (epsilon) and δ (delta). Most practical deployments use (ε,δ)-DP where δ accounts for the small probability of privacy failure. Smaller ε values mean stronger privacy but typically lower utility. Intuitively, DP ensures that each person’s data has almost no impact on the final synthetic dataset, making it highly uncertain whether their information was included at all.
When a synthesizer protects privacy using DP while generating data, that process is differentially private synthetic data generation (DP-SDG).
An Illustrative Example of Using DP for LLM Fine-tuning For Text Generation
Section titled “An Illustrative Example of Using DP for LLM Fine-tuning For Text Generation”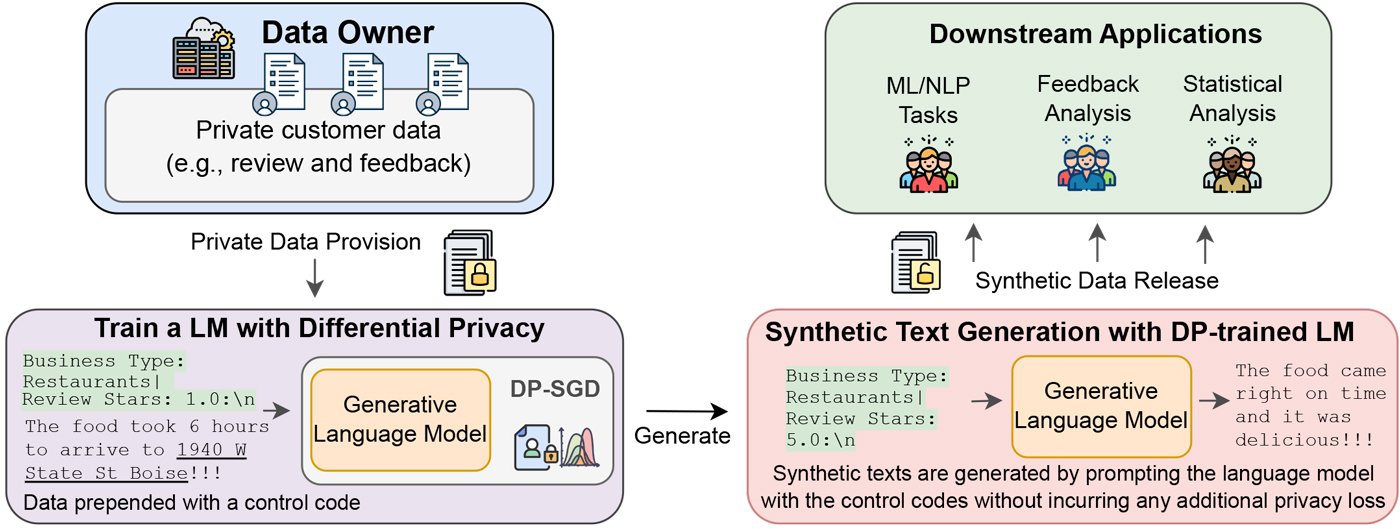
Figure 4: Researcher from Microsoft fine-tuned an LLM with DP on private
data corpus. The model can be used to generate synthetic examples that
resemble the private corpus.
Image reference:
Synthetic Text Generation with Differential Privacy: A Simple and Practical Recipe
An Example of Using Differentially Private Gaussian Copula for Tabular Generation
Section titled “An Example of Using Differentially Private Gaussian Copula for Tabular Generation”While various models can incorporate DP for synthetic data generation, the Differentially-Private Gaussian Copula serves as a practical example for tabular data. It introduces quantifiable mathematical bounds on privacy loss, providing rigorous, tunable safeguards against individual re-identification.
Copula-based models are computationally efficient and mathematically interpretable alternatives to resource-intensive methods like deep neural networks. They reduce training time and hardware requirements while mitigating the overfitting and mode-collapse risks common in neural networks. By utilizing Sklar’s Theorem, this approach fundamentally decouples the distribution of individual variables from the underlying dependency structure that binds them together.
How Gaussian Copula Works
Gaussian Copula offers a fast, easily interpretable way to replicate the global statistical properties of a dataset by capturing dataset-wide rank correlations through a single global matrix. Commonly implemented in libraries like the Synthetic Data Vault (SDV), the generation relies on a two-step framework:
- Marginal Modeling: The algorithm models the marginal distributions of each column independently, transforming the data into a uniform space, and subsequently into a standard normal space.
- Global Covariance: It computes a single, global covariance matrix in this latent space, effectively capturing the pairwise rank correlations of the source dataset.
To generate new data, the model samples from a multivariate normal distribution mapped to this matrix and applies the corresponding inverse transformation to each column to recover the mapped values in their original marginal distributions.
Applying Differential Privacy
During the training phase of a Differentially Private Gaussian Copula, formal privacy guarantees are achieved by injecting calibrated statistical noise into the dataset’s foundational statistics. This noise is injected using either the Laplace mechanism to achieve pure ε-Differential Privacy, or the Gaussian mechanism to yield approximate (ε,δ)-Differential Privacy. Specifically, the algorithm computes one-way marginal distributions and two-way attribute conjunctions, adding this calibrated noise to the query results rather than the raw data itself. These noisy measurements are then used to estimate the latent global covariance matrix. However, because independent noise injection often distorts the matrix and breaks its mathematical validity, an essential post-processing step projects it to its nearest positive semi-definite equivalent. Sampling from this structurally valid, privatized copula guarantees quantifiable privacy protection. Yet, like all DP mechanisms, it inherently introduces a privacy-utility trade-off, as both the injected noise and the subsequent matrix projection may degrade the statistical fidelity of the generated data compared to a standard non-private model.
Privacy isn’t a binary yes-or-no question—it’s about managing risk based on your specific context and threat model. Start with simple smoke tests to catch obvious issues, use attack-based evaluations for realistic threat assessment, and consider DP-SDG when you need formal guarantees with strong privacy protection.
The next chapter shifts focus to exploring practical synthesis considerations by taking a systematic, pipeline-driven approach that helps you generate useful synthetic data for your specific applications.
Footnotes
Section titled “Footnotes”-
Membership inference is trickier for data such as images, videos and audio. For e.g., even if a synthetic image is far away (in terms of some distance metric) from a real image, it could be perceptually similar, leaking the sensitive identity information. So “perceptual similarity” evaluation is critical for such data. ↩
-
In a recent empirical work, the authors systematically performed various attacks on synthetic data with differential privacy guarantees and demonstrated that it can still leak sensitive information. However, we argue that gaps in how differential privacy was applied may have contributed to these failures and then there is lack of details on the implementation. ↩