6. Practical Data Synthesis - Quality Guidelines from Tabular Perspectives
High-quality data requires more than just picking a synthesizer and running it on real data. Projects often fail when key steps are skipped—defining requirements (how the data will be used and what counts as success), data profiling, selecting an ill-fitting synthesizer, or evaluating narrowly—producing outputs that look convincing but lack utility or carry hidden risks. A systematic, end-to-end process improves results.
This chapter introduces the Synthetic Data Generation (SDG) Pipeline—a practical framework from our experience working on tabular data at GovTech. These guidelines help reflect on what works in practice. While focused on tabular data, many principles extend to other modalities.
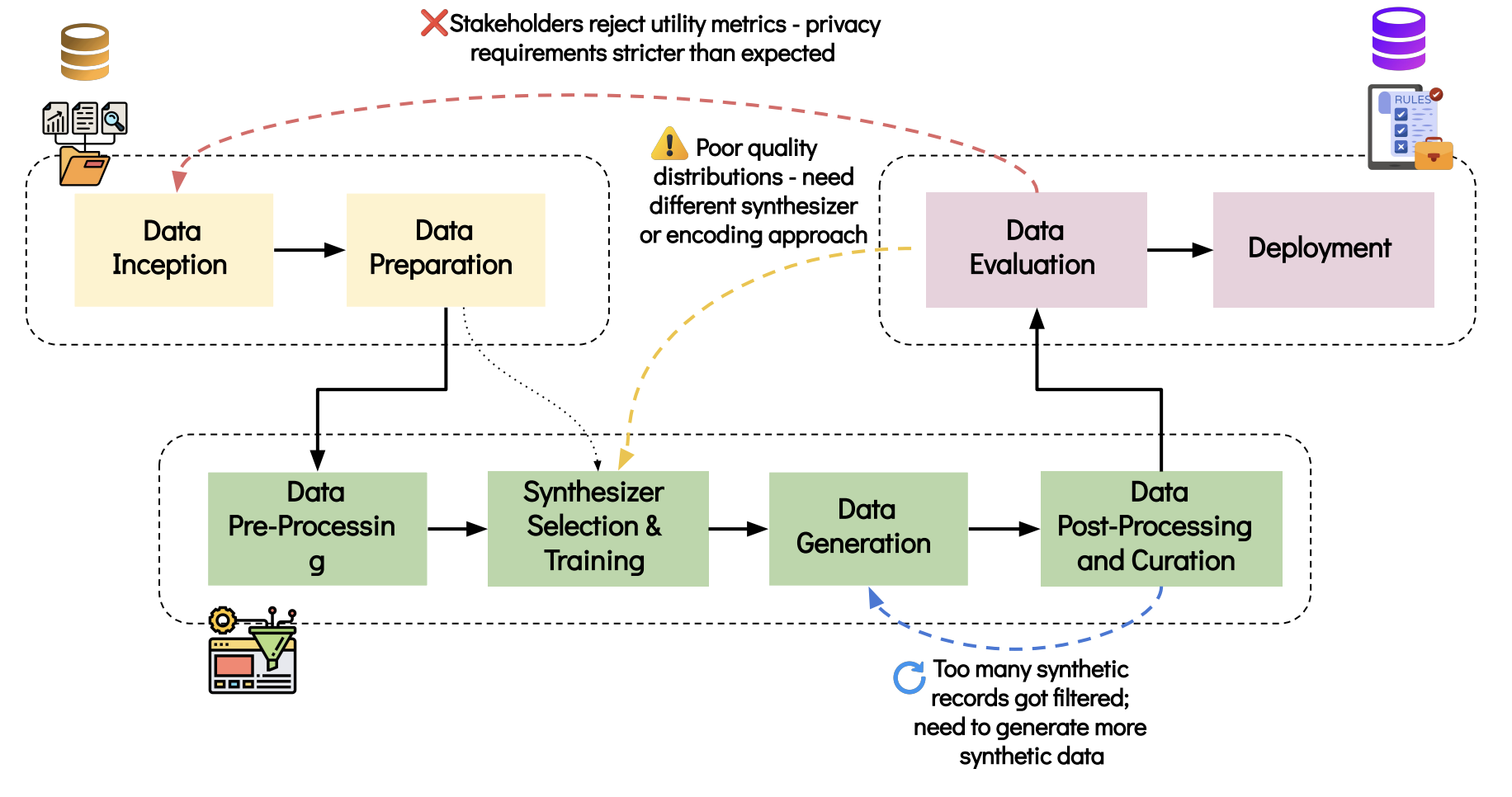
Figure 1: The SDG Pipeline. The framework shows eight key stages grouped
into three phases: planning and data preparation (yellow), core synthesis
(green), and validation and deployment (pink). Dotted arrows indicate the
non-linear nature of the pipeline, reflecting real-world SDG projects
where common patterns emerge—such as evaluation revealing the need for
data preparation refinements, model adjustments, or additional generation
cycles.
1. Data Inception (Planning and Scoping)
Section titled “1. Data Inception (Planning and Scoping)”A strong start sets direction for everything downstream. Before any modeling, assess how the availability, quality, and scale of the real data—and the constraints surrounding it—can shape every downstream decision. Before any technical work, define the use case, threat models, success criteria, and roles, ensuring the plan reflects what is realistically achievable.
Some key actions:
- Assess data availability and complexity — confirm data access, scale, and governance rules to anticipate synthesizer and infrastructure needs.
- Identify stakeholders (policy, legal, domain experts) and capture their needs early for aligned synthesis goals.
- Surface privacy/fairness/regulatory requirements upfront to avoid re-engineering synthesizers later.
- Agree on evaluation metrics to guide trade-offs and measure progress.
2. Data Preparation (Profiling and Cleaning)
Section titled “2. Data Preparation (Profiling and Cleaning)”SDG does not fix dirty data—errors, gaps, and biases propagate or worsen. Similar to any AI/ML task, preparation ensures accuracy, consistency, and representativeness in the real data before synthesizer training. Preparation involves actions like column profiling, resolving inaccuracies, handling missing values, and addressing anomalies.
Some column-level data preparation examples
| Column Characteristic | Why It Matters | Guideline | Example |
|---|---|---|---|
| High % missing values | Can produce unrealistic outputs | Analyze missingness mechanism (MCAR, MAR, MNAR); choose appropriate imputation strategy or drop if not feasible | Income: 70% missing → impute with median by job_category or drop column |
| High-cardinality categorical | Increases risk of memorization and slows training | Group rare categories; cap unique values | Job_title: 2000+ values → group rare ones as “Other_Professional” |
| Unique/compound identifiers | No statistical meaning; privacy risk | Remove or pseudonymize (replace with non-identifying codes) | SSN: “123-45-6789” → remove or hash to “ID_A7B9C2” |
| Highly correlated columns | Adds redundancy; can inflate feature importance | Merge or remove after verifying correlation isn’t meaningful | Height_cm & Height_inches (r=1.0) → keep Height_cm only |
| Inconsistent formats & errors | Hides true patterns; inaccurate data propagates to outputs | Standardize formats and units; validate and correct errors | Dates: “Jan-1-2023”, “01/01/23” → standardize to “2023-01-01” |
| Outliers/anomalies | Distorts distributions; can leak rare records | Assess; cap (limit to threshold), remove, or tag | Age: 999 → cap at 95th percentile (e.g., 75) or remove |
| Duplicate rows | Biases learning and wastes compute | Remove; prevent train/test leakage | Customer_ID=123 appears 3x → keep 1, remove 2 duplicates |
| Small categorical groups | Underrepresented in outputs | Merge or oversample (increase representation) | Country: 1-2 records each → group as “Other_Countries” |
| Numerical scaling/skew | Hinders synthesizer learning (for distance/gradient-based methods) | Normalize for neural networks/SVM; transform skewed distributions; skip for tree-based synthesizers | Income: $0-$1M → log-transform or normalize to [0,1] scale |
3. Data Pre-Processing (Synthesizer-Ready Transformations)
Section titled “3. Data Pre-Processing (Synthesizer-Ready Transformations)”Pre-processing transforms clean data from the data preparation step into formats that synthesizers can learn from effectively. Pre-processing involves actions like column encoding, removing derived/deterministic fields, restructuring constraints, and for time series data, setting the sequence length.
Some column-level data pre-processing examples
| Category | Why It Matters | Guideline | Example |
|---|---|---|---|
| Categorical encoding | Encoding choice affects learning and bias | One-hot for nominal; ordinal for ranked; target encoding for high-cardinality | Gender → [0,1] vs Education_level → [1,2,3,4] |
| Derived/deterministic columns (calculated from other columns) | Direct synthesis may break relationships due to random nature | Remove calculated fields; recompute after synthesis or enforce in post-processing | Drop total_price column; keep quantity & unit_price |
| Business constraints and rules | Some values must meet hard rules | Transform data structure to enforce constraints mathematically; reconstruct during post-processing | start_date < end_date → convert to [start_date, days_duration] where duration > 0 |
| Date representation | Must preserve logic | Exact dates (demographics): numerical encoding (e.g., year, month); Relative dates (sequential): anchor earliest date, convert rest to relative offsets | Birth_year → 1985; Transaction_dates → [0, 15, 23, 45] days from first |
| Sequential/temporal features | Synthesizers need structured time-aware inputs | Create lag features or use sequence-aware synthesizers | Previous_month_sales, 7-day_moving_average |
| Special cases (zip codes, IP addresses, etc.) | Require domain-specific handling to preserve accuracy | Apply specialized encoding or use domain-aware synthesizers | Zip_code → [state, region, population_density]; IP → [country, ISP_type] |
4. Synthesizer Selection and Training
Section titled “4. Synthesizer Selection and Training”Synthesizer choice has a direct impact on quality and privacy. Consider whether to use open-source, commercial, or in-house solutions, factoring in key considerations like technical expertise, budget, privacy needs, infrastructure, data complexity, and compute capacity. Like any AI/ML modeling, training requires careful setup and monitoring—establish validation metrics, configure compute resources, track training stability, and implement overfitting safeguards (e.g., early stopping, regularization).
Guidelines to consider in this stage:
- Choose a synthesizer that fits your data and constraints (refer to Generation Methods for guidelines) and preferably recent and up-to-date ones.
- Decide on your hyperparameter approach (use defaults for quick prototyping, manual tuning for optimal results, or automated search for systematic optimization)
- For large datasets, start small to test settings (train on 10K rows before scaling to 1M+), then scale up. This approach can save compute resources.
- Monitor for instability (overfitting to training patterns, mode collapse where outputs become repetitive, constraint drift where rules get violated during training)
- Keep seeds, configs, and dataset versions for reproducibility (essential for auditing and replicating results)
5. Data Generation
Section titled “5. Data Generation”Generation converts your trained synthesizer into actual records that match your target dataset structure. The level of control over what gets generated varies significantly and depends on the implementation of the synthesizer.
Guidelines to consider in this stage:
-
Choose a sampling strategy based on dataset size:
- Single pass for small datasets (under 10K rows)
- Batches of 1K-5K records for memory efficiency with large datasets
- Stratified sampling to maintain group proportions
-
Generate more than needed if filtering is likely (e.g., create 12K records if you need 10K final records)
-
Log seeds for reproducibility (e.g., set
random_state=42to ensure identical outputs across runs) -
Apply constraints during generation if your synthesizer supports it:
- Specify value ranges (e.g.,
age18-65 for adult customer data) - Enforce logical rules (e.g.,
start_date < end_date)
- Specify value ranges (e.g.,
-
Check interim outputs to catch anomalies early before generating the full dataset
6. Data Post-Processing and Curation
Section titled “6. Data Post-Processing and Curation”Post-processing transforms generated synthetic data to ensure they meet application requirements and business rules. This includes data decoding (converting encoded formats back to original representations), constraint validation, and format restoration. Curation involves selecting, filtering, and improving the quality of generated samples to create a final dataset that best serves the intended use case.
Guidelines to consider in this stage:
| Activity | Purpose | Examples |
|---|---|---|
| Enforce business rules | Ensure outputs meet logical constraints not guaranteed during generation | Logical constraints (start_date < end_date), valid ranges (age 0-120, positive monetary values), format validation (valid ZIP codes) |
| Recompute deterministic fields | Restore calculated values that were removed during pre-processing | Calculated values (total_price = quantity × unit_price), derived metrics (BMI from height/weight) |
| Restore application-ready formats | Convert encoded data back to usable formats | Convert encoded dates back to standard formats, transform categorical numbers back to text labels |
| Adjust representation balance | Match real data distributions if needed | Rebalance demographic groups, adjust class proportions, ensure minority representation |
| Curate for quality and relevance | Select and refine samples to maximize dataset value | Filter out low-quality and implausible samples, select diverse representative samples, remove harmful outliers, deduplicate if uniqueness required |
7. Data Evaluation (Including Risks)
Section titled “7. Data Evaluation (Including Risks)”Evaluation confirms whether synthetic data meets fitness-for-purpose requirements and acceptable risk thresholds. This stage validates quality across multiple dimensions before deployment. We covered comprehensive evaluation dimensions and metrics selection guidance in the Quality Evaluation chapter, with approaches for privacy assessment detailed in the Privacy-preserving Synthesis chapter.
Guidelines to consider in this stage:
- Evaluate for any privacy, legal and compliance risks
- Align metrics with the agreed purpose
- Ensure robustness by testing across runs, samples, and timeframes (SDG is stochastic in nature)
- Examine subgroups and rare cases, not just averages
- Validate against domain knowledge, use human-in-the-loop approaches (visual inspection, medical expert assessment), or external statistics
- Assess and balance conflicting dimensions (e.g., fairness vs. fidelity, privacy vs. utility)
8. Deployment Practices
Section titled “8. Deployment Practices”Deployment determines how data is accessed, maintained, and trusted over time.
Guidelines to consider in this stage:
- Decide how to publish (synthesizer, dataset, API) based on context and risk
- Get stakeholder agreement on scope and conditions
- Provide documentation proving minimal re-identification risk, describing the process, and confirming the synthesizer didn’t overfit
- Version and track datasets, synthesizers, and configs
- Monitor usage and refresh if data changes or metrics drift
This systematic approach works well for most SDG pipelines that require careful data preparation and a systematic approach. However, the process is rarely strictly linear; you may need to iterate between stages as you refine your approach. Additionally, not every project requires all eight stages—simpler use cases (e.g., requiring testing data where low utility suffices) might skip certain steps entirely.
Organizations should assess their specific SDG needs and adapt this framework accordingly, selecting the stages and depth of implementation that match their data complexity, privacy requirements, and resource constraints.
Large Language Models (LLMs) offer a different approach to generation that can complement or sometimes simplify the structured pipeline outlined above. The next chapter explores how LLMs are changing the landscape, providing both powerful new capabilities and more intuitive ways to generate content.