2. Applying Differential Privacy
Worked Example: A Differentially Private Count
Section titled “Worked Example: A Differentially Private Count”Suppose we want to count the number of survey participants in a differentially private manner. We add random noise to the count, drawn from a probability distribution with the properties needed to satisfy the definition of differential privacy. One such distribution is the standard Laplace distribution, denoted laplace(noise_scale). The mechanism that adds noise from this distribution to a query output is the Laplace mechanism. For a query output on dataset D:
laplace_mechanism(D, noise_scale) = query(D) + laplace(noise_scale)
noise_scale = sensitivity / εHere, sensitivity is the maximum possible change in a query’s output when an individual’s record is added or removed. This ensures enough noise is added to hide each individual’s contribution. The noise scale is directly proportional to the sensitivity and inversely proportional to ε.
For the count query, adding or removing one individual changes the result by at most 1, so its sensitivity is always 1. If we set ε = 0.01, then noise_scale = 1 / 0.01 for the Laplace distribution. The differentially private count is private_count = laplace_mechanism(D, noise_scale). Suppose the true count is 1,000. Running the mechanism multiple times produces different random values close to the true count, for example 1001.23 or 999.81. Adding or removing an individual still yields nearly accurate outputs for meaningful analysis and decision-making.
It is possible for an observer to determine which probability distribution the algorithm uses to estimate the distortion of the true output. However, the specific random value added on any given run remains unknown. This randomness, and the similarity of outputs, increases the uncertainty of inferring any individual’s contribution to the dataset.
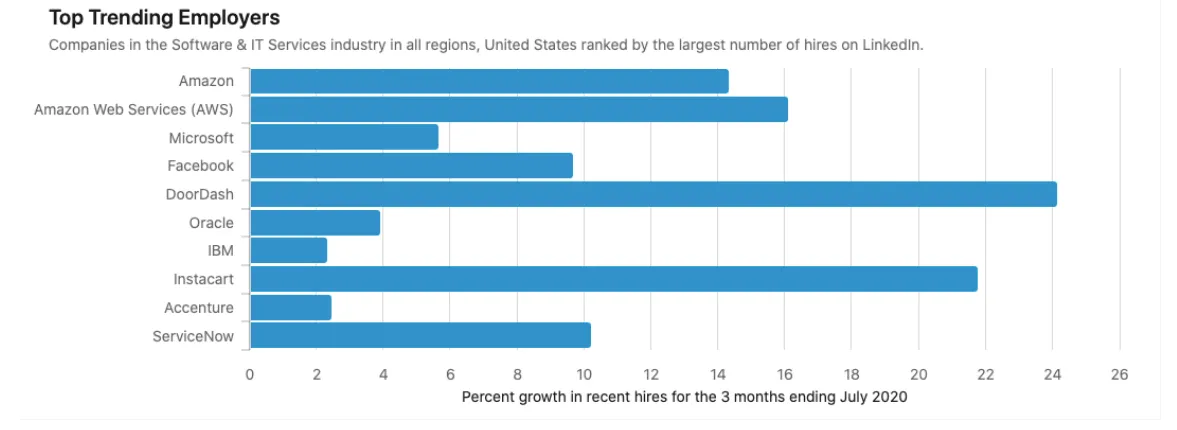
Real-World Example: LinkedIn Labor Market Insights
Section titled “Real-World Example: LinkedIn Labor Market Insights”This example shows the composition property in practice. LinkedIn used differential privacy to measure which employers were hiring the most, and their percentage growth in hires, using data from the current and previous three months, with a total ε = 14.4. Differential privacy protected LinkedIn users who may have changed jobs.
Each month’s report, for both the current and previous spans, cost ε = 4.8, adding up to a total of 14.4 (= 4.8 + 4.8 + 4.8) for three months.
Applications
Section titled “Applications”Differential privacy can be used for applications ranging from simple aggregate analysis, such as count queries and histograms, to machine learning tasks such as clustering, classification, and synthetic data generation.
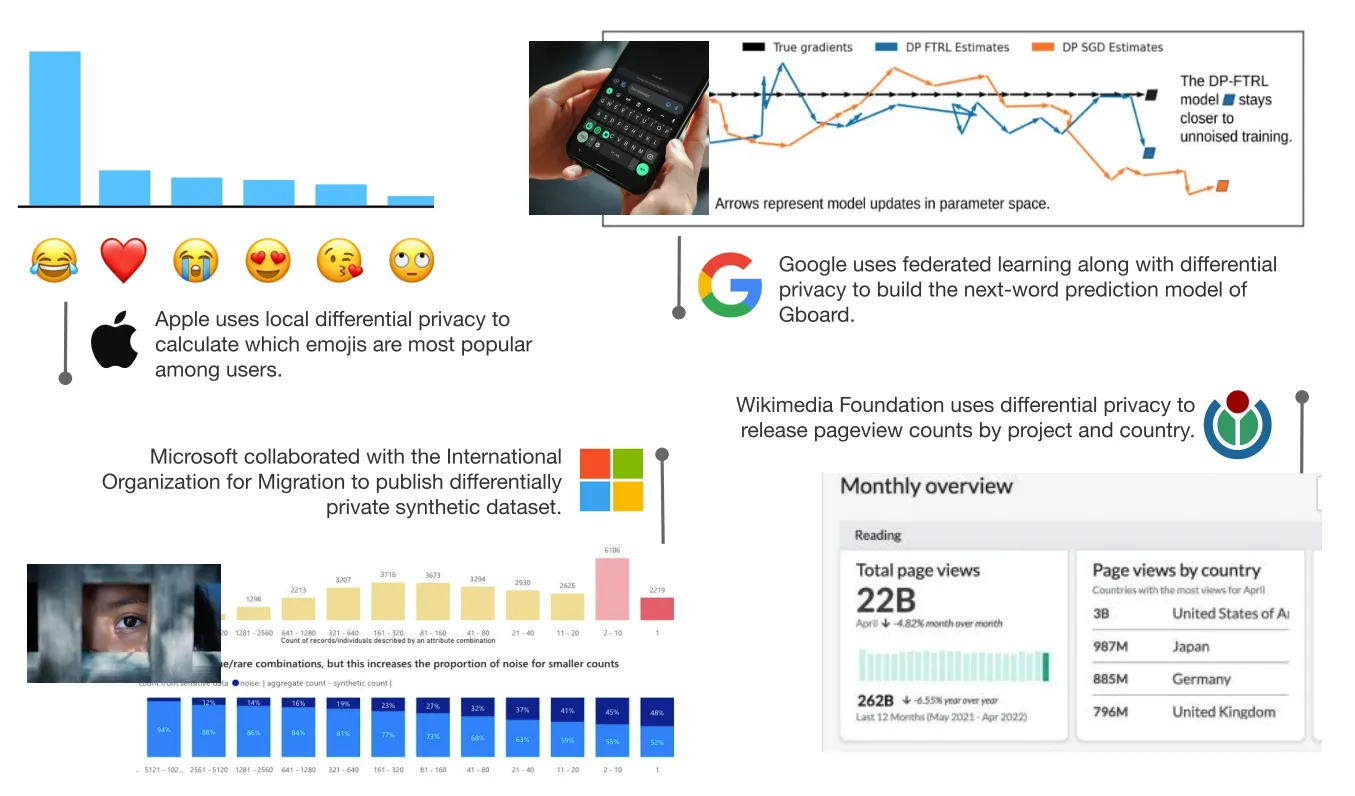
Well-known applications appear in companies such as Apple, Google, Microsoft, and the Wikimedia Foundation. In the government sector, the US Census Bureau adopted differential privacy to protect sensitive information in the summary statistics of the 2020 Decennial Census.