1. Identifying Privacy Risks
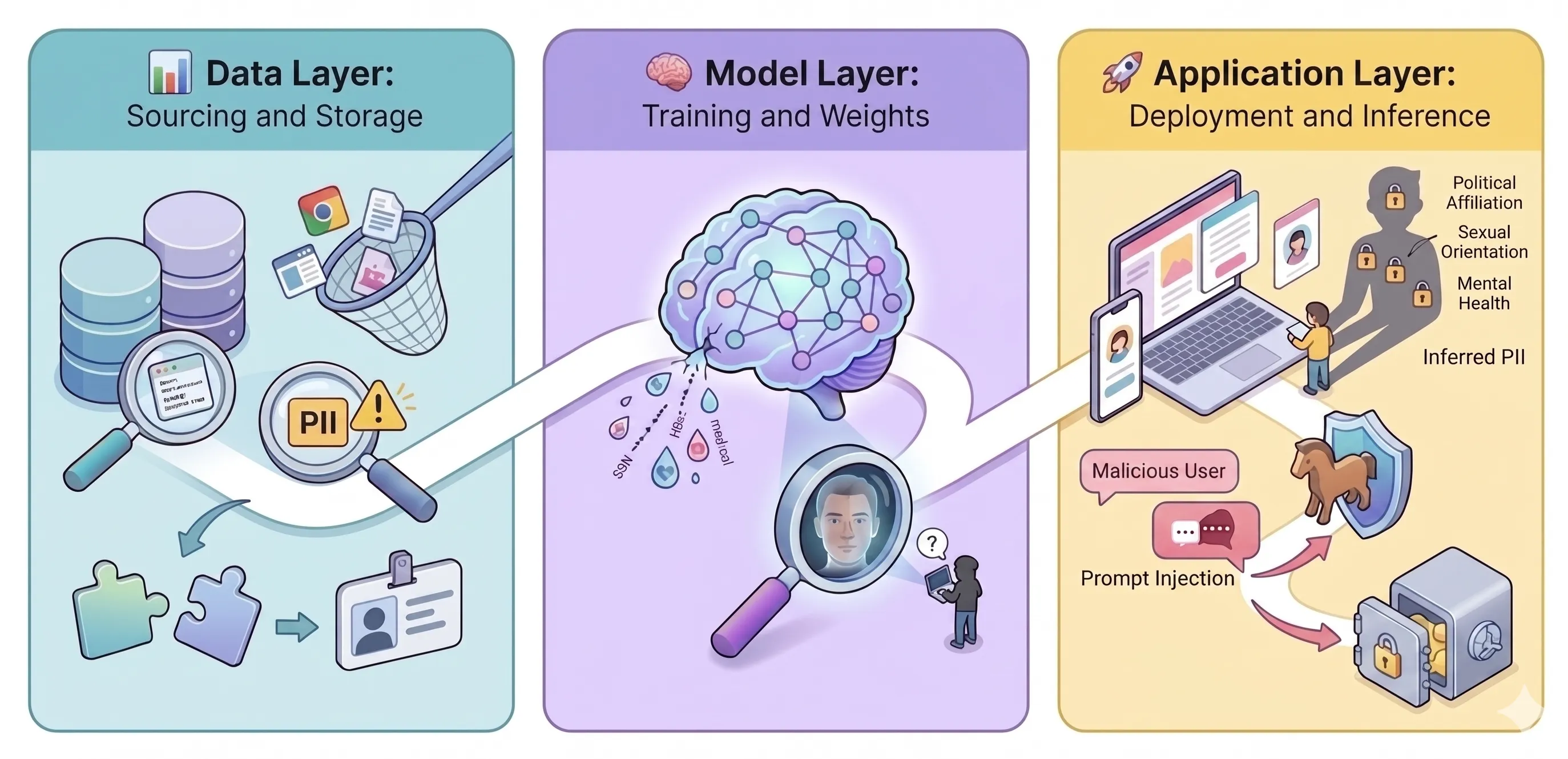
Identifying privacy risks across the three layers of the AI lifecycle (Data, Model, and Application). Image generated with Gemini.
To build responsible, privacy-preserving AI systems, we must first understand the privacy threats that manifest at each phase of the AI lifecycle. This chapter systematically uncovers how sensitive information can be compromised. We explore the vulnerabilities introduced within the data used to train and fine-tune models, the model training processes themselves, and the deployment phase where inference and user interactions occur. By deconstructing the AI ecosystem into three distinct layers (data, model, and application), we can pinpoint exactly where and how these vulnerabilities emerge, enabling us to address them directly at their source.
📊 Data Layer
Section titled “📊 Data Layer”The data layer encompasses the sourcing, curation, and storage of the vast datasets required for training, fine-tuning, and testing AI models. The primary privacy risks here stem from the sheer scale and indiscriminate nature of data collection.
Key Vulnerabilities:
- PII Embedded in Data: AI and ML systems rely on extensive historical, enterprise, or public data to identify underlying patterns. This broad data collection may result in Personally Identifiable Information (PII) becoming deeply embedded in training datasets without the data subject’s explicit knowledge or contextual expectation. For instance, customer data collected purely for transaction processing might be repurposed for a predictive ML model, or foundation models might ingest forum posts collected by scraping the internet.
- Re-identification of Anonymised Data: Traditional anonymisation techniques, such as data masking or pseudo-anonymisation, are increasingly vulnerable in the face of modern AI. Advanced algorithms can cross-reference multiple, seemingly disparate datasets to re-identify individuals from anonymised sets, exposing sensitive health, financial, or behavioural data.
🧠 Model Layer
Section titled “🧠 Model Layer”The model layer represents the underlying algorithm and its learned parameters. Even if data is legally acquired, the mathematical processes used to train models introduce unique privacy vectors based on how the model retains and reveals information.
Key Vulnerabilities:
- Data Memorisation & Extraction Attacks: High-capacity models, such as deep neural networks and LLMs with their massive parameter counts, often memorise exact examples from their training data. Adversaries can exploit this through extraction attacks (e.g., targeted prompt engineering in text models or specific noise inputs in image models) to force the model to reproduce sensitive training data. This can result in the leakage of sensitive information embedded within the training data.
- Membership Inference Attacks (MIA): Adversaries can query a model to determine whether a specific individual’s data was used in its training set. By analysing the model’s confidence scores or loss metrics which are typically higher for data the model has already “seen”, attackers can infer membership. Confirming that a person’s data was part of a highly specific corpus (e.g., HIV clinical trial dataset) inadvertently reveals sensitive information about the individual.
- Model Inversion Attacks: An attacker can exploit a trained machine learning model’s outputs (such as confidence scores) to reverse-engineer and reconstruct sensitive input data, such as private patient data, personal photos, or proprietary information used during training. By observing how the model responds to various inputs, the attacker can iteratively construct an input that perfectly represents a specific class or individual in the training data.
🚀 Application Layer
Section titled “🚀 Application Layer”The application layer is the interface where the model interacts with the end-user. Even if the training data is perfectly sanitised and the model itself is theoretically secure, the application architecture and user behaviours can introduce severe privacy failures.
Key Vulnerabilities:
- Prompt Injection and Data Exfiltration: Attackers can use adversarial prompts to bypass application-level guardrails, successfully manipulating the AI application into exposing proprietary data, session histories, or cross-user PII.
- Over-collection via Conversational Telemetry: Users often share deep, conversational, and often intimate details with Generative AI chat interfaces. Applications that indiscriminately log these interactions create massive, high-risk repositories of conversational PII. These logs are highly susceptible to internal misuse, unauthorised employee access, or external data breaches.
- Excessive Agency: For applications utilising Agentic AI, where the agent can independently invoke external tools, APIs, or database queries, the potential for unauthorised data exposure expands significantly. This introduces the privacy risk of excessive agency where an agent inherits broad backend permissions and bypasses traditional, user-centric data access controls. When vulnerable to direct user prompt injections or indirect prompt injections (e.g., malicious instructions hidden within ingested external webpages), the agent can be manipulated into over-fetching Personally Identifiable Information (PII) or inadvertently transmitting sensitive conversational context to unauthorised third-party tools.