2. Why Use Synthetic Data?
Organizations face persistent data bottlenecks: (i) privacy, regulatory and copyright limits; (ii) scarcity; (iii) bias, imbalance and unrepresentative samples; (iv) noise and missingness; (v) high collection cost; and (vi) cases where data simply does not exist. Major technology firms have publicly explored synthetic data approaches to meet growing data needs. We classify synthetic data’s solutions to these barriers into five capabilities.
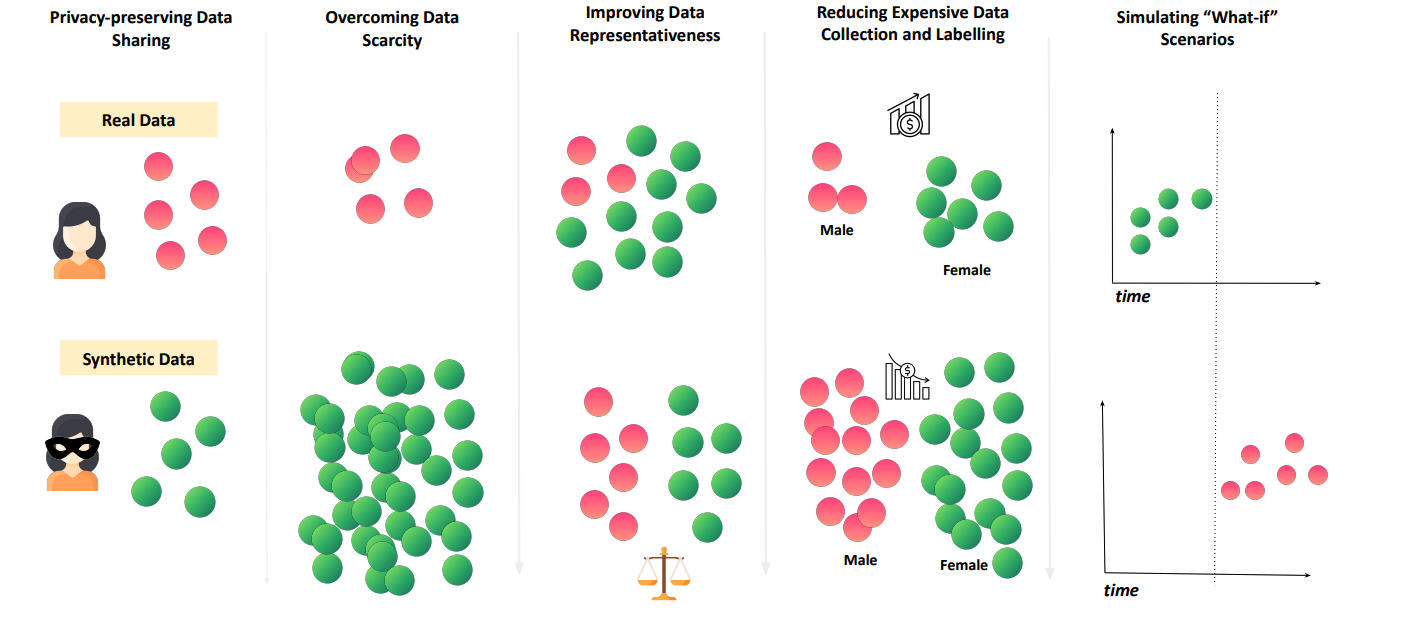
Figure: Capabilities of synthetic data addressing data challenges
1. Privacy-Preserving Data Sharing
Section titled “1. Privacy-Preserving Data Sharing”Synthetic data enhances privacy by replacing sensitive records with artificial yet statistically representative data. Instead of replicating individuals one-to-one, it aims to capture the general patterns, variability, and uncertainty of the source data. Synthetic data should therefore be viewed as a privacy-preserving approach when combined with safeguards (e.g., regularization, outlier handling, or differential privacy) within broader privacy-enhancing technology frameworks.
Example Applications: Cross-organizational data sharing for research and collaboration, and third-party sensitive data access for testing and development.
2. Overcoming Data Scarcity and Accessiblity
Section titled “2. Overcoming Data Scarcity and Accessiblity”Real-world data is often scarce, costly, or inaccessible due to privacy restrictions, proprietary ownership, collection difficulties, or limited sample sizes. Once a synthesizer is trained on available real data, synthetic generation can create substantially more samples. By expanding coverage of rare patterns, balancing underrepresented groups, and reducing the risk of overfitting to small datasets, synthetic data can improve machine learning model performance and enable analytics and research that would otherwise be impossible with limited real datasets.
Example Applications: Medical research with additional samples of rare diseases, and financial modeling with more examples of unusual market conditions or fraud patterns.
Data scarcity is especially acute for training and evaluating Large Language Models (LLMs)1: performance tends to improve as models and datasets grow together (with scaling laws). With limited human-generated data and concerns about contamination, synthetic data now plays a key role in sustaining LLM progress.
3. Improving Data Representativeness
Section titled “3. Improving Data Representativeness”Many real-world datasets underrepresent certain groups of people or situations based on demographics, race, conditions, or edge cases, leading to biased models that fail to generalize. Synthetic data can be generated with fairness constraints to improve data balance and train more equitable systems. This contributes to both representation fairness (all groups are included in the training data) and algorithmic fairness (model outputs are not skewed against any group).
Example Applications: Augmenting healthcare datasets to ensure rare conditions are represented in predictive models; generating balanced tabular data for loan approval systems across demographic groups; or creating diverse synthetic text corpora to reduce bias in language models.
4. Reducing Expensive Data Collection and Labeling
Section titled “4. Reducing Expensive Data Collection and Labeling”Data collection is often a significant bottleneck, with manual efforts like data labeling taking months and costing millions. Legal and privacy constraints may also prevent the reuse or commercialization of datasets. Synthetic data offers a faster, cheaper alternative by allowing the generation of tailored, task-specific datasets on demand. Additionally, synthetically generated annotations (e.g., preference ratings or intent labels) can offer more consistent and scalable alternatives to human-labeled data.
Example Applications: Bootstrapping a new customer service chatbot with thousands of labeled synthetic conversations categorized by intent (billing, technical support, complaints) before real interactions are collected; generating pre-labeled medical images to help prototype diagnostic models before large-scale expert annotations are available.
5. Simulating “What-if” Scenarios
Section titled “5. Simulating “What-if” Scenarios”Real-world data rarely covers edge cases, future events, or hazardous conditions needed for resilience testing. A synthesizer can create targeted “what-if” datasets by adding conditioning logic and recombining learned patterns under domain constraints. For e.g., it can pair normal traffic flows with extreme weather, or blend typical patient symptoms with a rare complication. This can provide scenario datasets that support autonomous vehicle stress tests and healthcare surge planning, subject to plausibility checks and validation.
Example Applications: Government agencies testing emergency response systems with simulated crisis scenarios (natural disasters, cyberattacks), and AI safety teams generating adversarial prompts to test model robustness against misuse attempts such as jailbreak prompts, hallucination, and bias probes.
The next chapter covers different synthetic data generation methods, providing the technical foundation for implementing these capabilities.
Footnotes
Section titled “Footnotes”-
The authors of the paper “Will we run out of data? Limits of LLM scaling based on human-generated data” project human-generated text data shortage for LLM training by 2026-2032 based on current scaling trends and suggest synthetic data generation as of the solutions to address the data bottleneck. ↩