8. Real-World Deployments
The transition from research to real-world implementation demonstrates the maturity and practical value of synthetic data. Across healthcare, government services, autonomous systems, and AI development, organizations are deploying synthetic data to overcome data challenges.
This chapter examines proven deployments that illustrate how synthetic data solves critical business challenges. We explore successful implementations across different sectors for diverse synthetic data generation (SDG) use cases.
Two detailed case studies provide in-depth implementation insights, while additional examples showcase the breadth of successful applications across industries.
Detailed Case Studies
Section titled “Detailed Case Studies”The challenge: Israel’s Ministry of Health faced a critical challenge: how to share valuable birth registry data for various stakeholders including non-medical1 researchers, other government agencies, journalists and the general public while protecting mothers’ and newborns’ privacy. Traditional anonymization methods like k-anonymity and data masking were insufficient for this sensitive medical domain.
The solution: SDG with Differential Privacy (DP) guarantees2 and an additional safeguard referred to as face privacy — aligning with people’s intuitive expectations of what counts as privacy-preserving microdata. In practice, this meant ensuring that records could not be trivially linked back to unique individuals, while acknowledging that “no unique records” alone is not a sufficient privacy guarantee. The dataset was released in February 2024 through extensive collaboration between a university’s researchers (who developed the implementation) and diverse Ministry of Health stakeholders using a co-design approach.
Implementation Approach
Section titled “Implementation Approach”Through co-design with diverse stakeholders, the team addressed four key requirements: robust privacy protection (DP), microdata format preferred by data users (researchers who would analyze the dataset), statistical accuracy for various analyses, and comprehensive documentation to prevent misuse.
They developed Universal DP — a comprehensive framework integrating DP-based privacy protection methods. The implementation used an iterative process:
- Model training: Used PrivBayes3 (a Bayesian network approach for differentially private generation).
- Generation: Created records with face privacy projection (removal of unique records that could enable re-identification)
- Quality evaluation: Assessed against acceptance criteria (minimum statistical utility benchmarks for key demographic analyses)
- Iteration: Repeated until release standards were met (predefined thresholds for statistical accuracy and privacy protection)
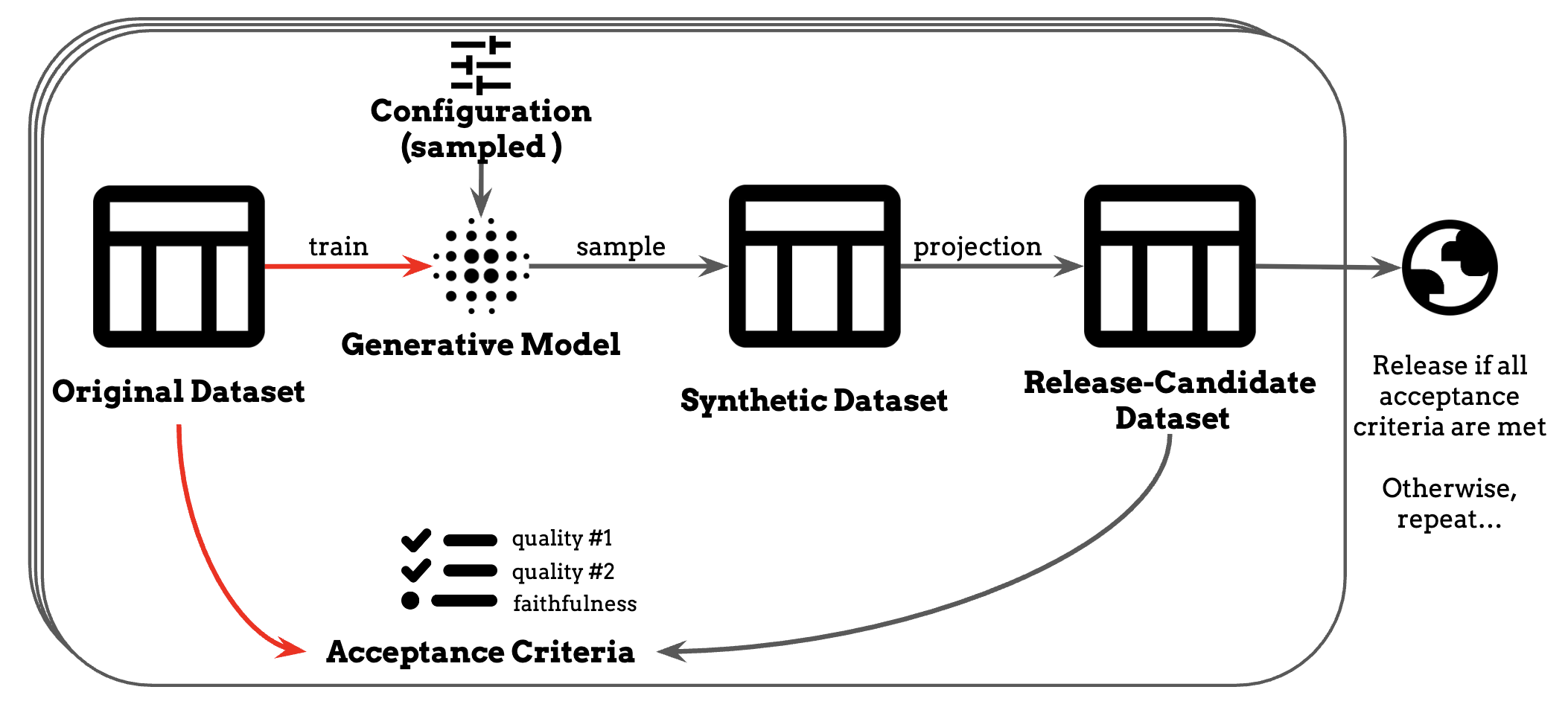
Figure 1: Iterative workflow from real dataset through generative model training, SDG, privacy projection, and quality evaluation before final release.
Image reference:
Differentially Private Release of Israel’s National Registry of Live Births
Technical Implementation: The team focused on 2014 singleton births, using six core data fields. They allocated a total privacy budget of ε=9.98. All processing occurred within a secure environment, with public data experiments used to optimize the approach before applying it to sensitive medical records. Implementation resources: SynthFlow, SmartNoise Core, IBM DP Library
Outcomes & Lessons
Section titled “Outcomes & Lessons”Impact Achieved: In February 2024, Israel released a government DP-protected medical dataset, complete with comprehensive documentation and open-source code. This established both a legal precedent and replicable framework for government agencies worldwide.
Key Lessons Learned:
- Stakeholder co-design: Essential for success but requires significant time and resource investment
- Documentation: Comprehensive guides prevent misuse and manage researcher expectations effectively
- Acceptance criteria–driven methodology: Clearly articulates privacy and utility requirements
- Robust privacy guarantees with DP: Traditional anonymization methods (k-anonymity, data masking) proved insufficient, requiring DP-SDG.
Current Limitations: The initial release covers only six data fields from a single year (2014). However, the Ministry of Health plans expanded releases incorporating additional fields and potentially other health registries based on researcher community feedback.
This pioneering deployment proves government agencies can successfully share highly sensitive data under strong privacy guarantees through systematic stakeholder engagement and technical innovation. The open-source methodology enables replication across health registries, census data, and other sensitive government datasets.
The challenge: Google needed to improve Gboard’s typing correction while protecting user privacy. The challenge was that mobile typing data is sensitive and cannot be directly collected, yet it differs significantly from the public web text typically used to train models, creating a domain shift that hurts performance.
The solution: The solution was to generate synthetic typing error data at scale and then curate it to match mobile typing behavior using privacy-preserving techniques. Role-playing prompts (such as ‘imagine an English school teacher’) combined with structured output formats were used to produce over 1.2M realistic error–correction examples. These synthetic samples were subsequently filtered and reweighted against privacy-safe signals from mobile devices—far exceeding the size of available real datasets, without ever accessing raw user data (see their paper for the LLM prompt template used.)
Implementation Approach
Section titled “Implementation Approach”-
Synthetic data generation: Because real keystroke and typing corrections are privacy-sensitive, Google generated millions of synthetic error–correction pairs as a safe substitute using prompt engineering.
-
Federated learning (FL) on devices: To align with real mobile typing patterns, lightweight models were trained directly on users’ phones using FL, ensuring raw data never left the device.
-
DP safeguards: These on-device models incorporated DP guarantees so they could not memorize or leak sensitive user inputs while ensuring they captured general typing patterns without memorizing sensitive inputs.
-
Buttress modules for reweighting: These DP-protected models were aggregated into multiple lightweight “buttress modules” (less than 100M parameters), each tied to a production metric (e.g., accept rate, next-word prediction). The modules scored synthetic samples, producing weights that aligned them with real mobile typing behavior.
-
LoRA fine-tuning of downstream models: The curated, reweighted synthetic dataset was then used to fine-tune task models efficiently with LoRA—first on synthetic data alone, then on mixtures of real and reweighted data.
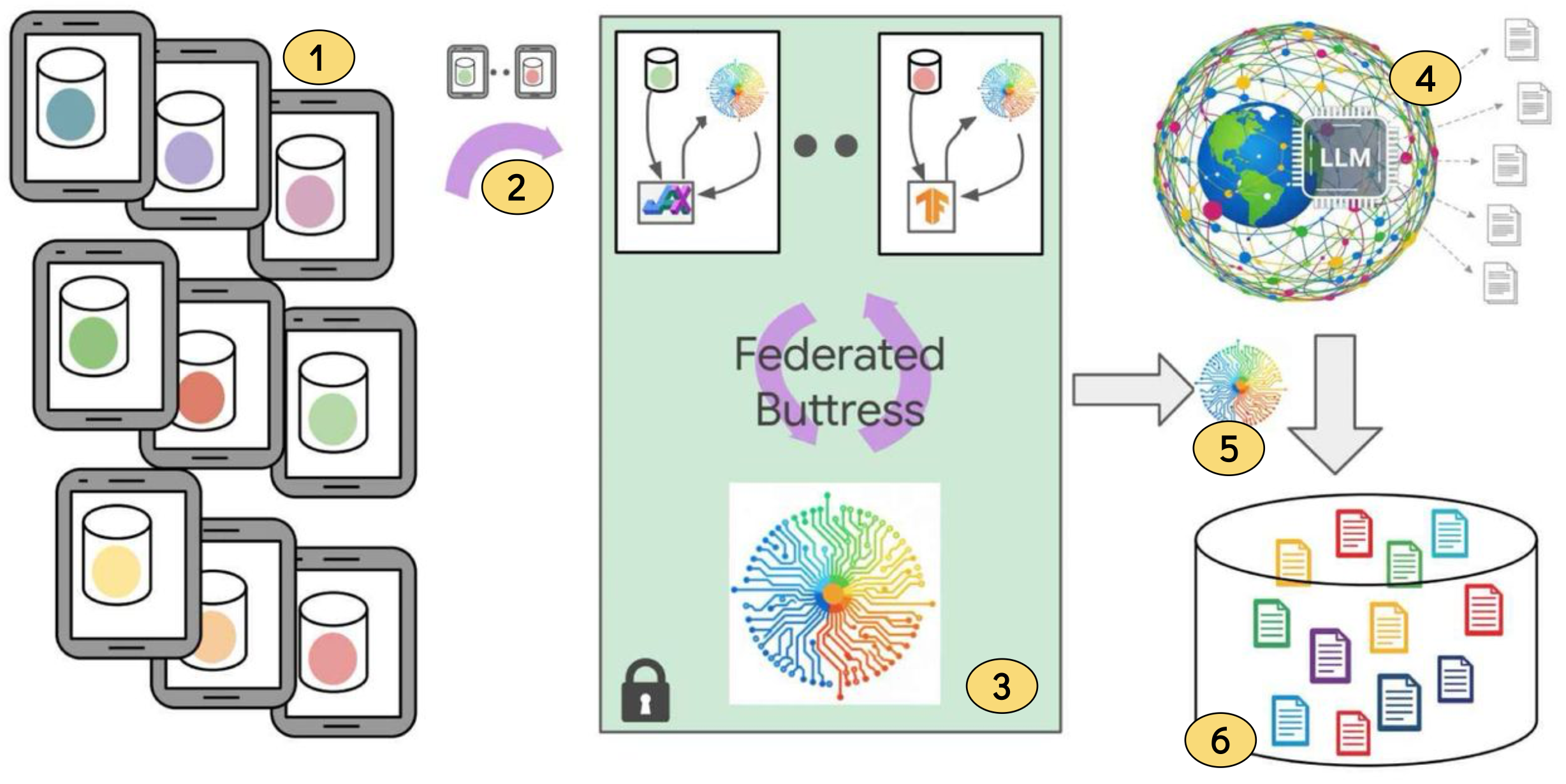
Figure 2: End-to-end pipeline for privacy-preserving training in Gboard. Key stages are: (1) User devices: Small LMs trained locally (via FL) to capture typing patterns. (2) DP-protected updates: Only noisy, aggregated weight updates are sent to the server. (3) Buttress module (FL + DP): Learns privacy-safe signals and prepares to score synthetic data. (4) Public LLMs: Generate large-scale synthetic error–correction pairs. (5) Reweighting: Buttress module scores and reweights synthetic data to match mobile typing behavior. (6) Curated dataset: Filtered synthetic data fine-tunes models (e.g., Gemini Nano) with multiple privacy safeguards.
Image reference:
Synthetic and federated: Privacy-preserving domain adaptation with LLMs for mobile applications
. We annotated the image for a better understanding.
Outcomes & Lessons
Section titled “Outcomes & Lessons”Impact Achieved: The strategy improved Gboard’s real-world performance, boosting user-facing metrics, increasing prediction accuracy, and reducing training costs — all under strong privacy guarantees.
Key Lessons Learned:
- Meticulous prompt engineering: With well-designed prompts and structured output formats, LLMs can scalably synthesize high-quality data that rivals small real-world datasets. LLMs themselves can also be used to verify correctness of the generated samples.
- Domain adaptation is necessary: Even high-quality synthetic data often requires alignment with real user behavior to perform effectively in production.
- FL + DP: Combining FL and DP allows models to benefit from in-domain signals while ensuring that sensitive user data never leaves the device.
- Defense-in-depth: Strong privacy protection comes from layering safeguards — auditing and inspecting synthetic data (with human-in-the-loop where needed), detecting and removing sensitive (PIIs) or hallucinated content — rather than relying on a single technique.
This deployment shows how synthetic data + FL + DP + privacy filters can enable accurate, privacy-preserving AI for citizen-facing services. The same approach could strengthen mobile government apps, digital identity systems, and citizen platforms — where safeguarding sensitive user data is critical.
Additional Real-World Deployments
Section titled “Additional Real-World Deployments”The following deployments demonstrate the versatility across different domains, data types, and organizational contexts:
| Synthetic Data Use Case | Key Challenge Solved | Impact Achieved | Capabilities Applied |
|---|---|---|---|
| Government sensitive health data sharing (UK’s NCRAS Simulacrum) | Cancer researchers needed patient data but couldn’t access real records due to privacy laws | Created synthetic cancer patient profiles that researchers can use freely, speeding up medical research while protecting real patients | Privacy-Preserving Data Sharing |
| Government census data sharing (US Census SSB) | Public researchers needed population insights but census data contains private citizen information | Generated synthetic population data that reveals social and economic trends without exposing any individual’s personal details | Privacy-Preserving Data Sharing |
| Autonomous vehicle safety training (Helm.ai) | Self-driving cars need to handle dangerous situations that are too risky to practice in real life | Created synthetic video simulations of rare driving scenarios (animals on roads, extreme weather) for safe AI training | Simulating “What-if” Scenarios + Overcoming Data Scarcity |
| Inclusive voice technology (Afro-TTS) | Voice assistants work poorly for people with African accents due to lack of training data | Generated synthetic voice samples for 86 African English accents, making voice technology more inclusive and accessible | Improving Data Representativeness + Overcoming Data Scarcity |
| AI assistant development (Stanford Alpaca) | Training helpful AI assistants requires expensive human-written instruction examples | Created 52K synthetic instruction-response pairs at low cost, enabling smaller organizations to build capable AI assistants | Reducing Expensive Data Collection + Overcoming Data Scarcity |
These real-world deployments show data addressing practical challenges across sectors. While each deployment has its own context and limitations, they demonstrate that synthetic data can move beyond research into operational use.
The next chapter explores potential applications within Singapore’s public sector for government officers working with citizen data, policy analysis, and public service delivery.
Footnotes
Section titled “Footnotes”-
Medical researchers can apply for a vetting process to gain access to the data within a monitored, enclave environment. ↩
-
While some view SDG as a privacy-enhancing approach because it reduces direct reliance on personal records, research consensus holds that strong privacy protection requires pairing it with formal safeguards such as differential privacy. ↩
-
PrivBayes has significantly influenced academic research and industry through widespread adoption in commercial platforms and open-source tools. It received the SIGMOD 2024 Test of Time Award for providing the first practical method to create synthetic datasets that preserve statistical accuracy while ensuring differential privacy. ↩