3. How to Generate Synthetic Data?
Synthetic data generators—often called synthesizers—are algorithms designed to learn from real data and generate new data points, aiming to mirror statistical properties and structural constraints. Understanding the classification of generation methods provides the foundation for implementing effective solutions.
This chapter provides an overview of synthetic data generation methods, explores how to choose the right synthesizer for your specific needs, and offers guidelines for benchmarking practices.
Classification of Synthesizers
Section titled “Classification of Synthesizers”Synthetic data generation (SDG) has evolved from statistical methods to advanced generative AI. Early methods relied on parametric distributions, Bayesian networks, and classical ML such as decision trees. Modern generative AI methods—including Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), autoregressive Transformers, normalizing flows, and Diffusion Models—excel at learning complex, multimodal, and skewed data patterns. Foundation models represent the latest frontier, leveraging extensive pre-training for contextual insights and enabling data augmentation through fine-tuning or prompt engineering.
We categorize SDG methods into three broad families:
-
Classical Modelling (Statistical + Traditional ML): Interpretable and efficient methods that capture basic distributions and dependencies (e.g., parametric distributions, Bayesian networks, copulas, decision-tree–based models, clustering).
-
Generative Models (Deep Learning): Neural architectures trained to learn complex, non-linear data patterns (e.g., GANs, VAEs, diffusion models, autoregressive transformers, normalizing flows).
-
Foundation-Model–based Generation: Large, pre-trained models adapted for synthetic data across modalities (e.g., large language models (LLMs), vision transformers (ViTs), multimodal foundation models).
Illustrative methodologies for SDG, shown here in the context of tabular data.
Section titled “Illustrative methodologies for SDG, shown here in the context of tabular data.”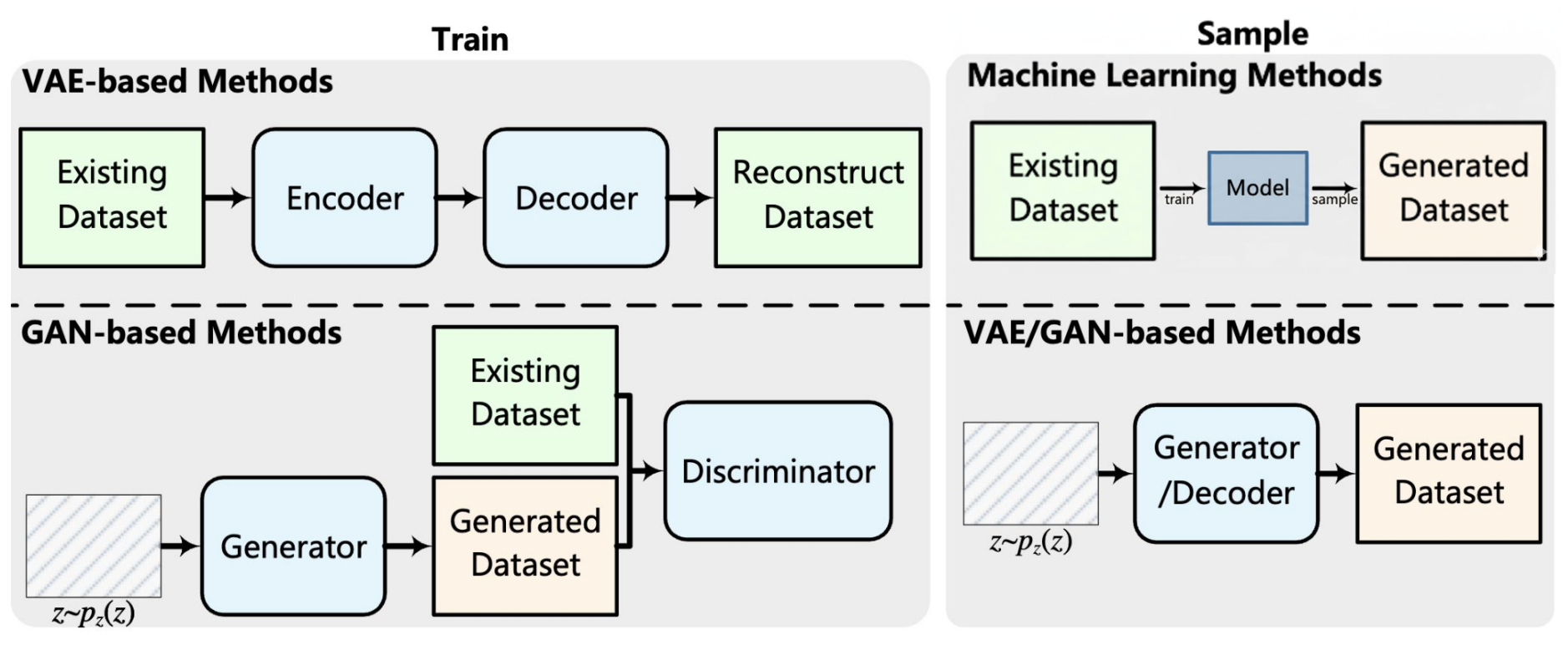
Figure 1: VAE-, GAN-based and traditional machine learning methods. VAEs
learn compressed representations of real data through an encoder–decoder
pipeline, enabling the generation of new records. GANs use a
generator–discriminator setup, where the generator produces synthetic data
and the discriminator distinguishes it from real data.
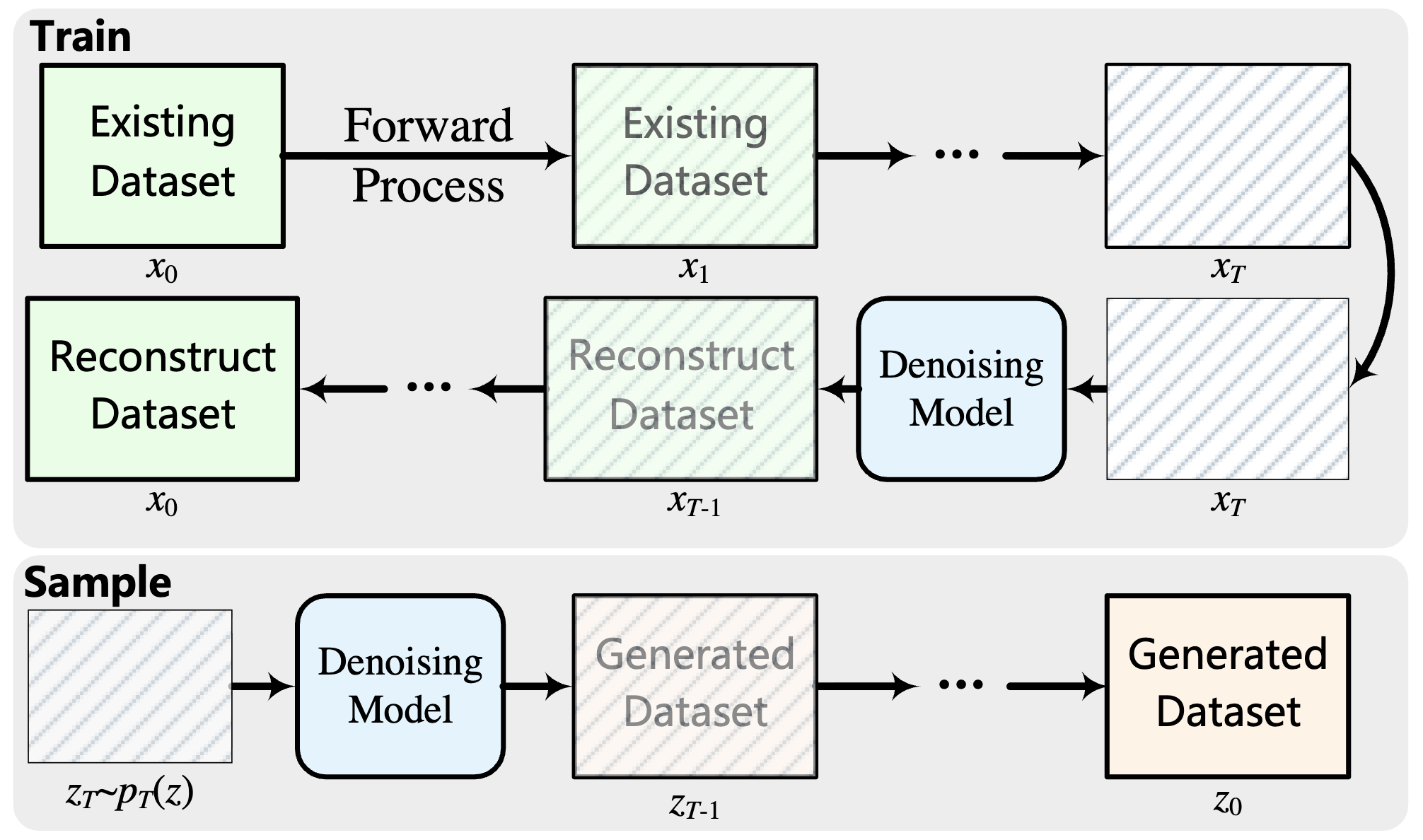
Figure 2: Diffusion models gradually corrupt real datasets with noise
during training and then learn to reverse this process (denoising). During
sampling, the trained model starts from random noise and iteratively
denoises it to generate synthetic records.
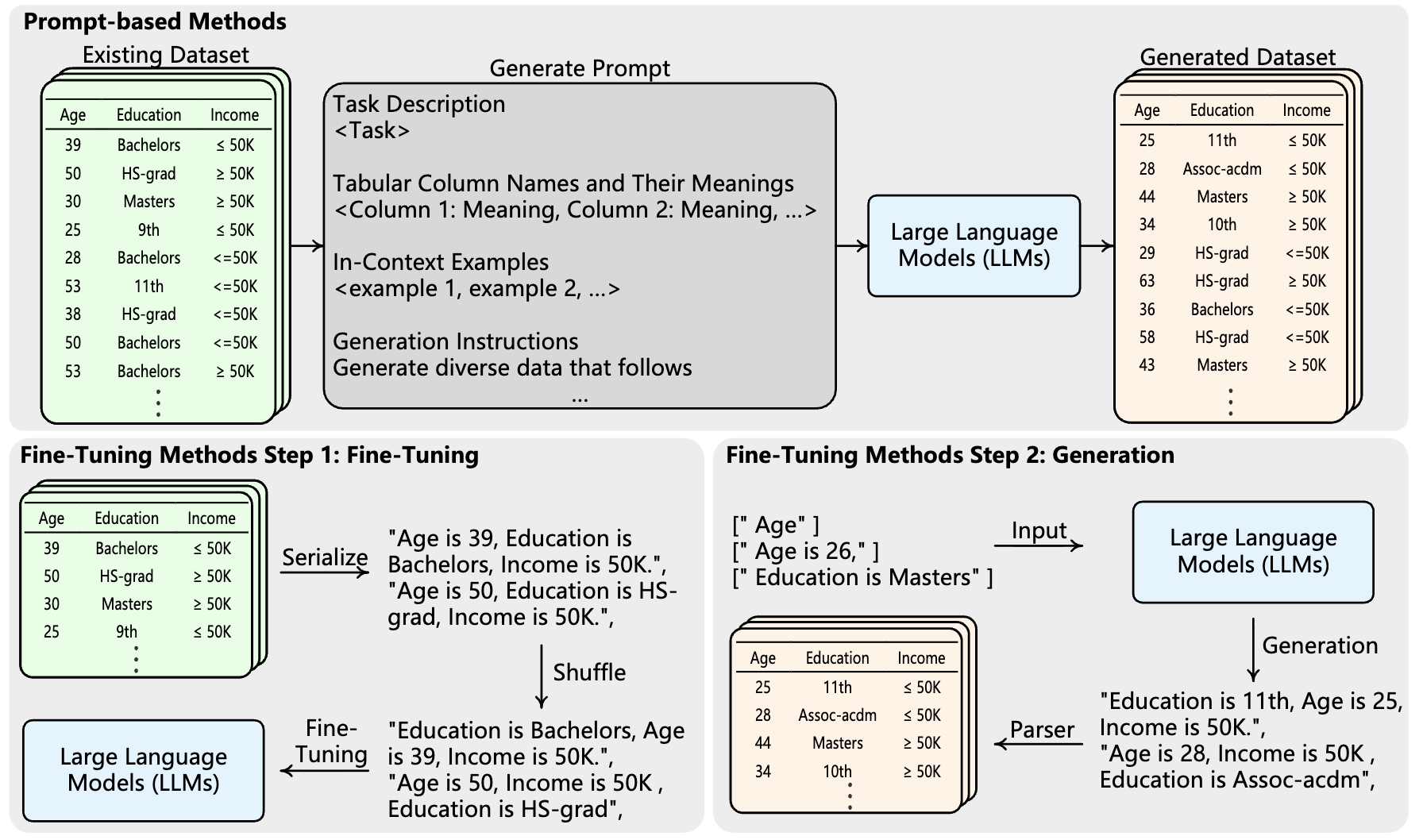
Figure 3: LLMs can generate synthetic tabular data either by crafting
prompts or by fine-tuning on real records.
Images reference:
A Comprehensive Survey of Synthetic Tabular Data Generation
Specifically, given the prevalence of LLMs for SDG, we have dedicated a chapter: LLM‑Driven Data Synthesis.
Key Considerations When Selecting Synthesizers
Section titled “Key Considerations When Selecting Synthesizers”The best synthesizer balances your data characteristics, use case requirements, and operational constraints—not necessarily the most complex model. There is no “one-size-fits-all” approach in SDG; each method excels in specific scenarios while having limitations in others.
Based on your needs, evaluate synthesizers across the following capabilities:
- Data characteristics (eliminates unsuitable methods): modality (tabular, time series, text, images), structural complexity (e.g., relational dependencies), data types and size etc.
- Quality requirements (sets performance expectations): testing applications may tolerate lower fidelity and prioritize compute efficiency, while production ML training often demands higher utility (usefulness) and fidelity (realism). (Refer to the chapter on Quality Evaluation for more details).
- Use case constraints (adds mandatory requirements): privacy needs (e.g., differential privacy support), fairness requirements, robustness to outliers, and adherence to dataset integrity constraints.
- Resources (determines feasible options): budget, compute power, time, and expertise. Deep learning methods often require significant hardware and tuning effort compared to classical modelling.
Practical Approaches to Get Started
Section titled “Practical Approaches to Get Started”-
Leverage GovTech’s Mirage: For Singapore public sector users, Mirage provides a toolkit spanning multiple generation methods, from classical models (e.g. Bayesian Network, Gaussian Copula, Differentially Private Gaussian Copula) to deep generative approaches (e.g. Denoising Diffusion Probabilistic Models, Adversarial Random Forest), designed for secure data sharing, AI/ML development, and software testing across government agencies.
-
Start simple: Begin with interpretable statistical models or ML approaches. They are computationally inexpensive, fast to run, and establish quality baselines. For e.g., GaussianCopula by SDV is fast to train and easy to use for initial prototyping.
-
Explore state-of-the-art (SOTA) models: Leverage recent open-source synthesizer implementations that may offer better quality than existing baseline models. SynthCity provides diverse SOTA models for tabular data generation, OpenDP for differentially private SDG or refer to standalone repositories by authors of recent models like RealTabFormer for multi-table generation.
-
Evaluate commercial solutions: If in-house expertise or capacity is limited, evaluate vendor platforms against your requirements—supported data types and constraints, privacy guarantees (e.g., differential privacy options and third-party audits), security and deployment model (on-prem/SaaS), integration and governance (APIs, lineage), and total cost. Review public benchmarks, peer-reviewed papers, and recent release notes or blog posts to validate methods and assess pace of progress.1
-
Benchmark systematically: The most reliable path is rigorous benchmarking—whether by referencing published studies or conducting your own evaluations tailored to your data and requirements. Refer to benchmarking reports and papers for guidance, such as TSGBench for time series.
The next chapter provides perspective on how to assess synthetic data quality, including considerations for metrics selection and understanding quality trade-offs.
Footnotes
Section titled “Footnotes”-
Notable vendors include Gretel.ai (now a part of NVIDIA), Mostly.ai, and Betterdata.ai. GovTech does not endorse any vendor; these are provided for readers to consider. ↩