9. Applications in the Public Sector
As we noted in the previous chapter on Real World Deployments, government agencies and enterprises are adopting synthetic data as a Privacy-Enhancing Technology (PET) and AI accelerator to address data bottlenecks while supporting responsible AI development, research, and innovation.
This chapter presents practical applications drawn from our public sector experience. We organize these into broad categories that span diverse use cases—from operational testing to AI development and secure data sharing—with insights applicable to both government agencies and enterprises worldwide.
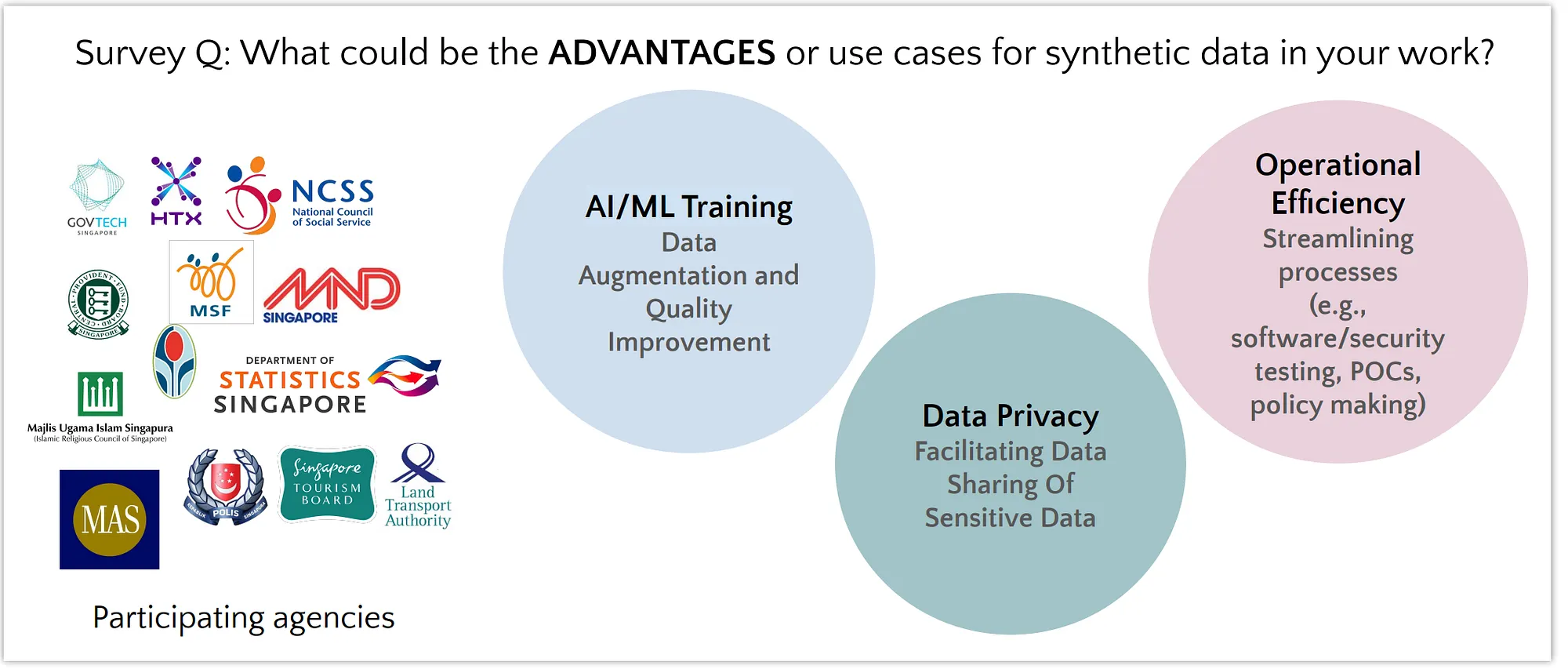
Figure: Survey by GovTech’s data privacy team showed varied potential
benefits of synthetic data use and interest across diverse Singapore
government agencies.
1. Safe and Scalable AI Development
Section titled “1. Safe and Scalable AI Development”AI is powering significant government applications, with innovation projects to solve real problems such as Named Entity Recognition (NER) for PII detection in sensitive documents, LLM-powered assistance systems, and multimodal AI-assisted cataloguing. Synthetic data is proving valuable for training, testing, and evaluating AI/ML models—particularly where data scarcity, non-existence or sensitivity limits access to real datasets for government applications.
Example Applications
Section titled “Example Applications”- Dataset Augmentation: Enhance training datasets for classification and regression tasks where real government data is limited, enabling more accurate AI-driven policy analysis and evidence-based decision-making.
- Representation Enhancement: Generate records for vulnerable or under-represented groups to improve model fairness and inclusivity across diverse citizen demographics.
- Data Imputation: Fill missing or erroneous values with synthetic ones. Hardware readings often contain gaps—synthetic data can help complete these with statistically representative values, such as filling missing utility-meter data.
- Scenario and System Testing: Generate datasets to test AI models against hypothetical situations—for e.g., computer vision systems detecting unusual pedestrian behavior or validating Retrieval-Augmented Generation (RAG) [^1] systems with diverse synthetic queries before production deployment.
Footnotes
Section titled “Footnotes”-
The UK’s National Health Service (NHS) operates an “artificial data” service that provides researchers with access to over 200 healthcare datasets in artificial form. This service helps users understand data structure, fields, and approximate value ranges before applying for access to real patient data. Notably, this system uses a purely statistical approach—employing classical statistical distributions, frequency sampling, and percentile-based generation—rather than machine learning algorithms. This design choice prioritizes transparency, regulatory compliance, and privacy essential for healthcare applications, though it means the artificial data cannot preserve complex relationships between fields. ↩