7. LLM-Driven Data Synthesis
Large Language Models (LLMs) have emerged as powerful tools for synthetic data generation (SDG), offering unprecedented flexibility and contextual understanding. This chapter explores how to leverage LLMs effectively for creating high-quality synthetic datasets across various domains and use cases. The widespread use, accessibility and practical usefulness of LLMs warrants a dedicated focus with this chapter.

Figure 1: Meticulous prompt engineering to generate diverse textbook
samples, leveraging the diversity of audiences (from left to right: young
children, professionals, researchers, and high school students) and
styles.
Image reference:
Hugging Face’s Cosmopedia blog
Why Are LLMs Powerful for SDG?
Section titled “Why Are LLMs Powerful for SDG?”LLMs exhibit a range of capabilities that make them especially powerful for SDG:
- Broad knowledge representation and pattern combination: They internalize complex probability distributions and dependencies across data and therefore can generate coherent and novel combinations by understanding how elements interact.
- In-context learning: They adapt to new tasks with just a few examples provided in the prompt.
- Controllability through prompting: Users can guide generation through instructions, constraints, and formatting specifications, providing fine-grained control over synthetic data characteristics.
- Emergent reasoning: At scale, LLMs gain unexpected abilities like multi-step problem solving, in-context learning, and abstract reasoning — enabling them to generalize, infer, and reason beyond surface patterns.
- Structured outputs: Modern models handle cross-modal inputs (text, images, audio) and generate structured outputs (tables, code, JSON).
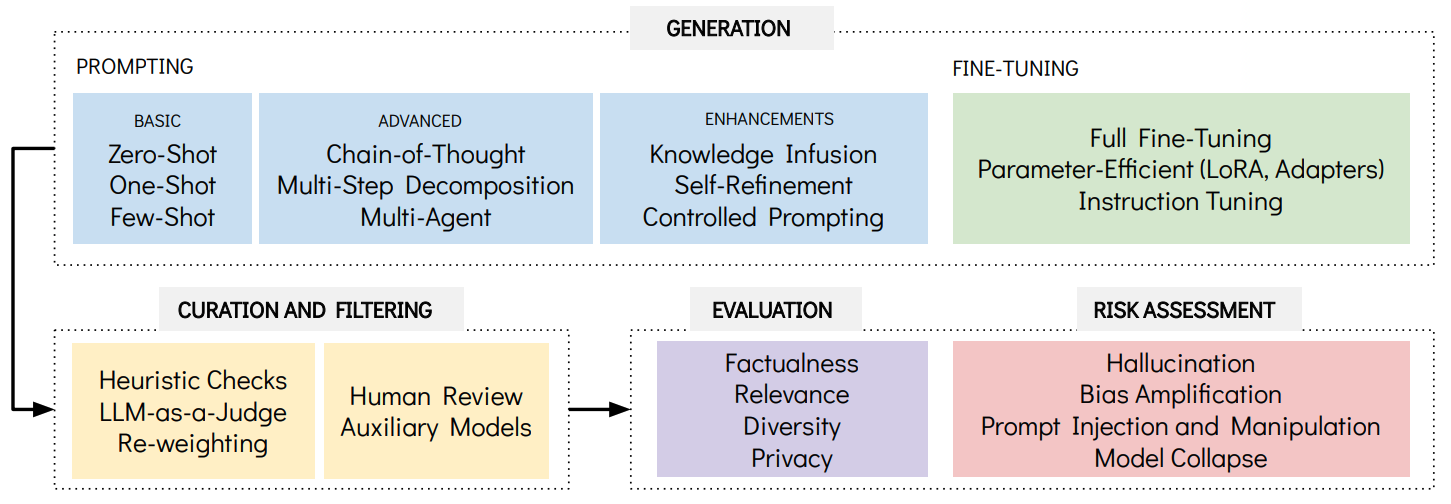
Figure 2: Key methodologies and considerations covered in this chapter,
organized into four main categories: Generation techniques (from basic
prompting to fine-tuning), Curation and Filtering methods for quality
control, Evaluation metrics for assessing synthetic data quality, and Risk
Assessment for identifying potential safety concerns. The arrows indicate
the typical workflow.
Generation Approaches
Section titled “Generation Approaches”LLM-driven SDG follows two primary approaches: prompt-based generation and fine-tuning, each offering different advantages for different use cases and resource constraints1.
The approaches introduced in this chapter are illustrative, not exhaustive, as the field is evolving rapidly.
1. Prompt-Based Generation
Section titled “1. Prompt-Based Generation”Prompt engineering forms the foundation of LLM-driven SDG, enabling practitioners to guide models toward desired outputs through carefully crafted instructions and examples.
1.1. Core Prompting Strategies
Section titled “1.1. Core Prompting Strategies”Zero-Shot Prompting
Section titled “Zero-Shot Prompting”Uses the model’s pre-trained knowledge without providing examples, suitable for generating common data types where the model’s training provides sufficient context.
Example:
Generate 10 synthetic citizen feedback entries for Singapore'sHealthHub digital services. Include variety in sentiment (positive,neutral, negative) and feedback length. Make them realistic butnot based on real citizens.One-Shot Prompting
Section titled “One-Shot Prompting”Provides a single example to establish format and style. While this improves output consistency, it may reduce diversity as the model anchors to the specific example.
Example:
Here's an example of a synthetic citizen service request:
{ "request_id": "MSF-2024-001", "citizen_name": "Tan Wei Ming", "age": 42, "district": "Jurong West", "service_type": "eldercare_assistance", "request_details": "Seeking home care support for elderly parent", "priority_level": "medium"}
Generate 5 more synthetic citizen service requests following this exact format.Few-Shot Prompting
Section titled “Few-Shot Prompting”Includes a few carefully selected examples that demonstrate task variety and desired characteristics. Multiple examples help models understand the range of acceptable outputs while maintaining consistency.
Example:
Here are examples of synthetic public officer feedback on digital transformation:
Example 1 (Positive, Tech Officer - GovTech):"The new automated workflow system has reduced our processingtime by 40%. Excellent support from the technical team."
Example 2 (Constructive, Policy Officer - PMO):"Digital tools are helpful, but we need better training forsenior officers. Perhaps structured upskilling programmes."
Example 3 (Mixed, Service Delivery - MSF):"Citizens appreciate the online portal, but the backend integrationwith legacy systems still causes delays in approvals."
Generate 8 more synthetic public officer feedback entriescovering different agencies and transformation aspects.1.2. Advanced Prompting techniques
Section titled “1.2. Advanced Prompting techniques”Chain-of-Thought (CoT) Prompting
Section titled “Chain-of-Thought (CoT) Prompting”Guides the model through explicit reasoning steps before generating final output, particularly valuable for creating logically consistent data.
Example:
Generate synthetic policy recommendation documents for Singapore's Smart Nation initiative.
Think step by step:1. First, identify a specific Smart Nation domain (transport, healthcare, urban planning, etc.)2. Consider the current challenges in that domain3. Propose evidence-based solutions4. Structure as formal policy recommendation with rationale
Generate 3 policy recommendations following this reasoning process.Sample Step-by-Step Reasoning:
Policy Recommendation 1 - Urban Transport:Domain: Intelligent Transportation SystemsChallenge: Peak hour congestion in CBD areasEvidence: Traffic data shows 35% increase during 8-9 AMSolution: Dynamic road pricing with AI-optimized ratesRationale: Reduces congestion while generating revenue for infrastructure...Multi-Step Decomposition
Section titled “Multi-Step Decomposition”Breaks complex generation into sequential components that build upon each other, ensuring consistency across different data elements.
Example:
Create synthetic citizen journey data for Singapore's digital government services.
Step 1: Generate citizen profile (age, needs, digital literacy level)Step 2: Based on profile, determine likely government services neededStep 3: Map the digital touchpoints for each serviceStep 4: Generate realistic interaction patterns and outcomes
Execute all steps for 5 different citizen personas.Sample Step-by-Step Output:
Step 1 - Profile: "Senior citizen, 68, moderate digital literacy, needs healthcare services"Step 2 - Services: "HealthHub appointment booking, medication delivery, specialist referrals"Step 3 - Touchpoints: "Mobile app (struggles), web portal (prefers), ServiceSG counter (fallback)"Step 4 - Journey: "Initial app attempt → web portal success → 3 appointments booked"Multi-Agent Prompting
Section titled “Multi-Agent Prompting”Multi-agent prompting uses agents—specialized LLM roles (e.g., Generator, Validator, Refiner)—that coordinate across turns so one drafts data, another checks it, and a third fixes issues; agents can be separate models or the same model with different system prompts/seeds.
Sample Three-Agent Workflow:
Roles:
Agent 1 (Generator): Create synthetic inter-ministry collaboration scenarios for whole-of-government initiatives.
Agent 2 (Validator): Review each scenario for:- Realistic ministry roles and responsibilities- Proper inter-agency coordination mechanisms- Alignment with Singapore's governance structure
Agent 3 (Refiner): Enhance scenarios with specific details:- Add relevant policy frameworks- Include realistic timelines and resource allocation- Ensure cultural and operational authenticityExample Exchange:
Generator: "MOM and MOH collaborate on foreign worker health screening..."Validator: "Scenario is realistic, but missing MND's role in dormitory regulations"Refiner: "Enhanced with Infectious Diseases Act framework, 2-week screening timeline, and proper inter-ministry MOU structure"1.3. Quality Enhancement
Section titled “1.3. Quality Enhancement”Knowledge Infusion
Section titled “Knowledge Infusion”Enhances LLM outputs by incorporating external information in the prompt, improving factual accuracy and relevance. This can be achieved through external knowledge sources such as RAG (Retrieval-Augmented Generation), knowledge graphs2, or retrieval augmentation from websites.
Example: Using RAG, Retrieve relevant information → Include in prompt context → Generate data based on facts
Task: Generate synthetic policy Q&A for housing policies
Step 1 - Retrieve: Get current HDB eligibility criteria from official sourcesStep 2 - Context: Include retrieved facts in promptStep 3 - Generate: Create Q&A pairs based on verified information
"Question: What are the income requirements for first-time BTO applicants?Answer: Based on current HDB guidelines, the monthly household incomeceiling is $14,000 for non-mature estates and $7,000 for mature estates..."Self-Refinement
Section titled “Self-Refinement”Enables the LLM to iteratively improve its own outputs through self-critique and revision cycles.
Process: Generate initial output → Self-critique → Revise → Repeat until satisfactory
Example:
Initial: "The policy allows citizens to apply for housing."Self-critique: "This is too vague and lacks specific details."Refined: "Citizens aged 21 and above with monthly household income below$14,000 can apply for Build-To-Order (BTO) flats in non-mature estates."Controlled Prompting
Section titled “Controlled Prompting”Uses structured prompts, constraints, and templates to guide generation toward desired outputs while maintaining consistency.
Example:
Generate diverse synthetic citizen complaints for Singapore government agencies.
Controlled Parameters:- Agency: Rotate through [HDB, IRAS, LTA, NEA, PUB]- Sentiment: [Frustrated, Constructive, Urgent, Appreciative]- Complexity: [Simple query, Multi-step issue, Policy clarification]- Channel: [Online form, Phone call, Walk-in, Email]- Demographics: [Young professional, Family with children, Senior citizen, New resident]
Generate 20 complaints ensuring balanced distribution across all parameters.2. Fine-Tuning Methodologies
Section titled “2. Fine-Tuning Methodologies”While prompt engineering is flexible, fine-tuning might be required when one needs specialized behavior, consistent output formatting, or optimization for specific organizational use cases.
-
Full Fine-Tuning: Update all LLM parameters on task-specific datasets for maximum customization.
-
Parameter-Efficient Fine-Tuning (PEFT): Update only a small subset of parameters, keeping most of the pretrained model frozen. This reduces compute cost and preserves general knowledge.
- LoRA (Low-Rank Adaptation): Adds small trainable matrices while keeping base weights frozen.
- Adapter methods: Insert small trainable modules between layers for domain or style specialization.
-
Instruction Tuning: Fine-tune on diverse instruction–response datasets to improve general task-following and formatting.
Curation and Filtering
Section titled “Curation and Filtering”LLM-generated data needs systematic curation to mitigate hallucinations, inconsistencies, and quality variations. Effective curation ensures synthetic data aligns with downstream requirements through two main strategies:
Sample Filtering Identify and handle low-quality outputs.
- Heuristic checks: Rule-based validation, confidence thresholds, or domain-specific quality signals.
- LLM-as-a-judge: A separate LLM evaluates outputs against explicit criteria, sometimes in ensembles for reliability.
- Re-weighting: Instead of binary accept/reject, assign weights to emphasize more useful samples while retaining diversity.
Label Enhancement Improve or standardize annotations.
- Human review: Experts validate data in critical domains (high cost but high reliability).
- Auxiliary models: Smaller specialized models refine or correct labels at scale; active learning can route only uncertain cases to humans.
Evaluation and Risk Management
Section titled “Evaluation and Risk Management”LLM-generated synthetic data requires adapted evaluation and risk management approaches that extend beyond the other SDG methods.
Evaluation
Section titled “Evaluation”The dimensions introduced in the Quality Evaluation chapter still apply, but in the LLM context they take on additional nuance:
-
Factualness: Verifies that generated content is accurate and internally consistent. Methods include cross-referencing with authoritative sources, domain expert validation, and entailment-based consistency tests (using natural language inference models to check if one statement logically follows from another). For e.g., if the model outputs “Singapore is in Asia,” this is consistent with “Asia contains Singapore,” while “Singapore is in Europe” would be flagged as a contradiction.
-
Relevance: Ensures the data supports the intended application. Methods include task-specific performance testing, alignment scoring, and end-user validation. For e.g., synthetic fraud data should improve a fraud detection model’s precision, not just look realistic in isolation.
-
Diversity: Confirms broad coverage across scenarios, demographics, and edge cases. Techniques include statistical sampling analysis, n-gram repetition checks, and demographic audits. For e.g., a health dataset should not only cover common conditions like flu but also rare cases like epilepsy, ensuring minority representation is preserved.
-
Privacy: Guards against memorization or leakage of sensitive training data, including the risk of generating highly realistic but fabricated individual records. Approaches include membership inference tests, leakage detection tools, manual red-teaming, and compliance checks. For e.g., if an LLM generates (regurgitates) a real patient’s name and diagnosis that was present in its training data, privacy safeguards should flag and block that output.
Risk Assessment
Section titled “Risk Assessment”LLM-driven generation introduces specific risks that require proactive controls:
-
Hallucination: LLMs may produce plausible but incorrect outputs that mislead analysis or training. Mitigations include RAG with trusted sources, expert review, structured review workflows, and human oversight in sensitive domains.
-
Bias Amplification and Content Issues: LLMs may reinforce societal biases or generate inappropriate outputs, including offensive or copyrighted content. Mitigations include demographic bias audits, fairness constraints, balanced prompts, content filtering, and evaluation by diverse teams.
-
Prompt Injection and Manipulation: Malicious or adversarial prompts can subvert controls and trigger unsafe or low-quality outputs. Mitigations include validated prompt templates, input sanitization, content filters, and regular adversarial testing.
-
Model Collapse: Repeated training on synthetic outputs can degrade quality and reduce diversity as models “forget” reality. Mitigations include mixing synthetic with real data, applying quality-control filters, and verifying outputs to prevent compounding errors.

Figure 4: Model Collapse occurs when AI models are trained repeatedly on
their own outputs, gradually losing fidelity and diversity—like making a
copy of a copy. The sequence (right) shows a diffusion model retrained on
its own images: faces become increasingly warped and lose detail with each
iteration.
Image reference (left):
The Curse of Recursion: Training on Generated Data Makes Models Forget research paper
(right):
Nepotistically Trained Generative Image Models Collapse research paper
Understanding these evaluation criteria and limitations enables responsible deployment of LLM-generated data, ensuring benefits are balanced against potential risks.
The next chapter covers the real world deployments across diverse sectors and for diverse use cases.
Footnotes
Section titled “Footnotes”-
While resource constraints are often cited as bottlenecks in SDG, this interesting post by Anyscale’s co-founder states that compute resources can help us achieve high-quality synthetic data by enabling advanced approaches like reasoning, multi-step thinking, task decomposition, and agentic workflows. ↩
-
Microsoft Research introduced the SYNTHLLM framework for SDG (2025), a novel approach to SDG that constructs and leverages a “global concept graph” of high-level topics and key concepts within a domain (in this work, the authors focused on mathematics). It enables systematic sampling and recombination of diverse concepts across multiple documents, providing “knowledge-infused” prompts to the LLM and leading to the generation of unique, diverse, and complex questions. ↩