10. Challenges And Risks in Synthetic Data
Despite synthetic data’s success in real-world deployments, significant challenges1 remain—ones that can derail projects or erode trust if ignored. The promise comes with new complexities across technology, ethics, operations, and regulation. Success depends on taking proactive steps to address these constraints early, choosing mitigations deliberately, and building systems that hold up under scrutiny.
While not exhaustive, this chapter focuses on five key challenges.
1. Misuse, Disinformation, and Misinformation Risks
Section titled “1. Misuse, Disinformation, and Misinformation Risks”Synthetic data capabilities enable both intentional disinformation campaigns and unintentional misinformation spread that can be produced at scale with lower barriers to entry than traditional methods. While synthetic content quality varies, the accessibility of these tools allows bad actors to generate large volumes of plausible content, while also making it easier for false information to spread unintentionally when people cannot distinguish synthetic from real content. This threatens both individual privacy and societal trust in information authenticity that can lead to significant harms. For instance, spammers increasingly use Large Language Models to craft more convincing synthetic messages and personalized scams, while well-meaning users may unknowingly share synthetic content believing it to be authentic.
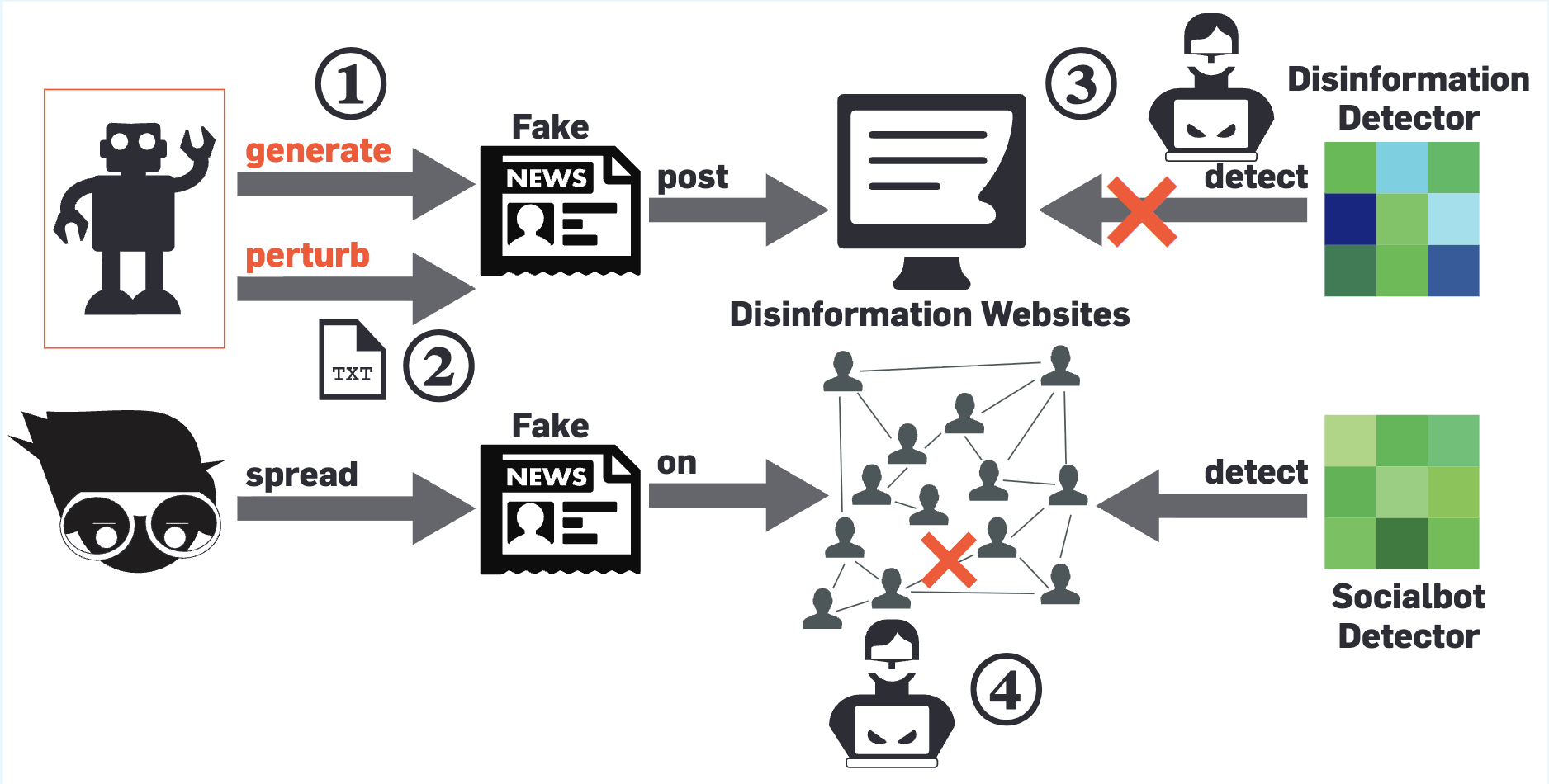
Figure 1: Adversaries generate more convincing disinformation, using
generative AI techniques (for e.g., ChatGPT for texts or DALL-E for
images); 2. Adversaries subtly perturb existing content using AI methods
to create more convincing disinformation with better capability to evade
detection; 3. Adversaries use AI methods to attack disinformation
detection ecosystems, promoting disinformation and demoting real news; 4.
Adversaries strategize the spread of disinformation using AI methods,
maximizing its influence on the (social) network while evading socialbot
detection ecosystems.
Image reference:
Disinformation 2.0 in the Age of AI: A Cybersecurity Perspective
Organizations must implement ethical guidelines, deploy detection mechanisms such as watermarking (such as DeepMind’s SynthID), establish transparency standards, and support AI regulatory frameworks (such as Monetary Authority of Singapore’s and NIST’s AI risk management frameworks) that balance innovation with protection against malicious use. Furthermore, organizations should also consider implementing robust tracking and validation systems, continuous human oversight, and AI-powered auditing to ensure the quality and trustworthiness of synthetic data.
2. Conflicting Objectives and Evaluation Inconsistency
Section titled “2. Conflicting Objectives and Evaluation Inconsistency”Synthetic data must balance competing goals that often conflict—improving one objective typically degrades others. Over-sampling minority groups improves fairness but distorts distributions; retaining outliers enables fraud detection but increases re-identification risk; adding privacy noise reduces analytical accuracy.
Current evaluation approaches treat each objective in isolation, missing critical interactions. Practitioners often optimize single metrics while inadvertently harming others, creating synthetic data that excels in one area while failing in others. Organizations need multi-objective evaluation frameworks that explicitly model trade-offs, establish clear priority hierarchies, and develop metrics that capture interactions between objectives rather than optimizing single metrics in isolation.
3. Bias Amplification vs. Overcorrection Dilemma
Section titled “3. Bias Amplification vs. Overcorrection Dilemma”Synthetic data faces a fundamental challenge: preserving legitimate patterns while avoiding harmful bias amplification. Generative models inherit biases from source datasets, potentially amplifying historical discrimination in hiring, lending, or healthcare. However, overcorrecting through aggressive fairness constraints creates the opposite problem—artificially balanced demographics that ignore legitimate patterns and obscure actual discrimination requiring attention.
Examples of the dilemma:
-
Medical research: Historical clinical trial data shows gender imbalances because women were historically excluded from studies. Should synthetic data replicate this imbalance (preserving the legitimate pattern of historical exclusion) or artificially balance it (potentially obscuring the real problem of underrepresentation that needs addressing)?
-
Financial lending: Credit approval data may show legitimate income-based patterns alongside discriminatory practices. Synthetic data must preserve real economic relationships while eliminating unfair bias—but distinguishing between these requires careful analysis.
Organizations must distinguish between harmful bias requiring elimination and legitimate patterns reflecting real phenomena. This requires analyzing source data to identify harmful versus legitimate patterns, engaging domain experts and affected communities, and establishing clear principles for when synthetic data should reflect current reality versus model aspirational improvements.
4. Differential Privacy (DP) Implementation Gap
Section titled “4. Differential Privacy (DP) Implementation Gap”Differentially private synthetic data has been sought after as a promising solution for privacy-preserving synthetic data generation. While real-world deployments (e.g., Israel’s medical data sharing) show that differentially private synthetic data can be applied in practice, implementation challenges persist. Correct DP implementation requires specialized expertise to provide meaningful privacy guarantees.
Practitioners face a fundamental dilemma when choosing privacy parameters (epsilon and delta values that control the privacy-utility trade-off). Setting parameters too restrictively makes synthetic data insufficiently useful for analysis. Setting them too permissively provides inadequate privacy protection, with higher epsilon values offering progressively less privacy. Key challenges include:
- Utility loss: DP limits the amount of information the synthesizer can extract from the real dataset, often reducing utility especially for rare events, outliers, and minority groups. Small datasets are particularly affected.
- Choosing ε: There is no universal consensus on what constitutes an acceptable ε; the “right” value depends on the threat model, data sensitivity, and acceptable utility loss
- Implementation complexity: Requires careful configuration and validation; incorrect implementations can undermine guarantees. Teams are advised to seek expert advice, use well-vetted, open-source or commercial DP libraries
- Transparency requirements: When deploying DP-generated data, disclose what constitutes a “record” (privacy unit—the individual entity being protected, typically one person’s or entity’s data), and the chosen ε and δ values for proper interpretation and reproducibility
Progress requires developing practical parameter selection frameworks, improving privacy-utility optimization techniques, and creating standardized evaluation methodologies that guide implementation decisions across different organizational contexts.
5. Enterprise Deployment Complexity
Section titled “5. Enterprise Deployment Complexity”Synthetic data deployment in large organizations faces significant technical and non-technical barriers that often prove more challenging than the underlying technology itself. Research identifies over 40 distinct challenges spanning governance coordination, organizational transformation, and infrastructure complexity.
The coordination challenge is particularly acute. Synthetic data projects require unprecedented collaboration between data scientists, data stewards, legal teams, and business users who operate with different priorities and timelines. Legacy systems often lack integration capabilities, existing governance frameworks prove inadequate for synthetic data, and stakeholders require extensive education before trusting synthetic alternatives in critical processes.
Organizations might benefit from executive sponsorship, cross-functional governance structures, phased implementation approaches that start with lower-risk use cases, and systematic attention to organizational barriers alongside technical development.
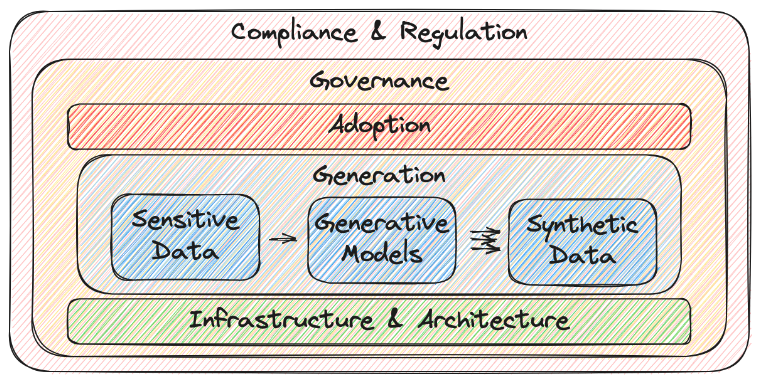
Figure 2: A research work identified 40+ challenges of deploying
privacy-preserving synthetic data in large enterprises, categorized into
five groups: generation, infrastructure & architecture, governance,
compliance & regulation, and adoption.
Image reference:
On the Challenges of Deploying Privacy-Preserving Synthetic Data in the Enterprise
These represent key challenges organizations encounter when deploying synthetic data. While researchers continue developing solutions, organizations must exercise discretion and adopt context-appropriate approaches, treating these challenges as design constraints rather than deal-breakers.
Finally, there’s a social challenge: will practitioners trust synthetic data? There’s often a perception that AI-generated data isn’t “real” and it won’t work in practice. Building confidence requires transparency about creation and rigorous quality evaluation. For high-stakes applications (medical, legal), regulatory requirements and privacy assessment may be necessary.
The next chapter looks at where synthetic data is headed—new techniques that are making it more practical, emerging applications, and the research that’s solving today’s challenges.
Footnotes
Section titled “Footnotes”-
The article by Straits Times “Tech companies are turning to ‘synthetic data’ to train AI models – but there is a hidden cost” emphasizes the critical need for robust global tracking and validation systems, continuous human oversight, and even AI-powered auditing to ensure the quality and trustworthiness of synthetic data, thereby preserving the future accuracy of AI. ↩